 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuery Complexity of Clustering with Side Information
Paper and Code
Jun 23, 2017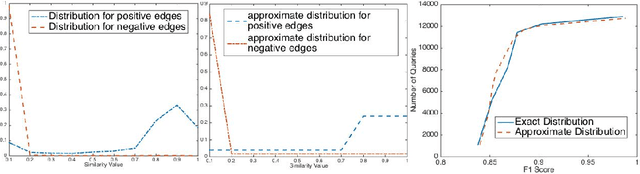
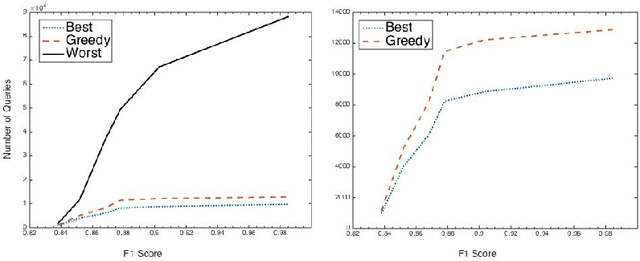
Suppose, we are given a set of $n$ elements to be clustered into $k$ (unknown) clusters, and an oracle/expert labeler that can interactively answer pair-wise queries of the form, "do two elements $u$ and $v$ belong to the same cluster?". The goal is to recover the optimum clustering by asking the minimum number of queries. In this paper, we initiate a rigorous theoretical study of this basic problem of query complexity of interactive clustering, and provide strong information theoretic lower bounds, as well as nearly matching upper bounds. Most clustering problems come with a similarity matrix, which is used by an automated process to cluster similar points together. Our main contribution in this paper is to show the dramatic power of side information aka similarity matrix on reducing the query complexity of clustering. A similarity matrix represents noisy pair-wise relationships such as one computed by some function on attributes of the elements. A natural noisy model is where similarity values are drawn independently from some arbitrary probability distribution $f_+$ when the underlying pair of elements belong to the same cluster, and from some $f_-$ otherwise. We show that given such a similarity matrix, the query complexity reduces drastically from $\Theta(nk)$ (no similarity matrix) to $O(\frac{k^2\log{n}}{\cH^2(f_+\|f_-)})$ where $\cH^2$ denotes the squared Hellinger divergence. Moreover, this is also information-theoretic optimal within an $O(\log{n})$ factor. Our algorithms are all efficient, and parameter free, i.e., they work without any knowledge of $k, f_+$ and $f_-$, and only depend logarithmically with $n$. Along the way, our work also reveals intriguing connection to popular community detection models such as the {\em stochastic block model}, significantly generalizes them, and opens up many venues for interesting future research.