 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantized Neural Networks: Characterization and Holistic Optimization
Paper and Code
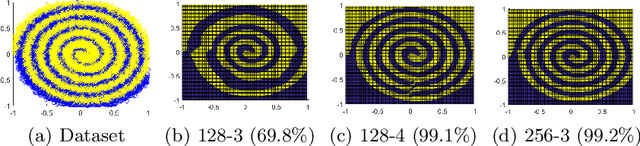
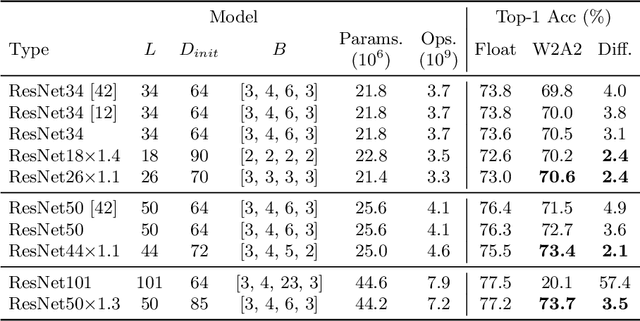

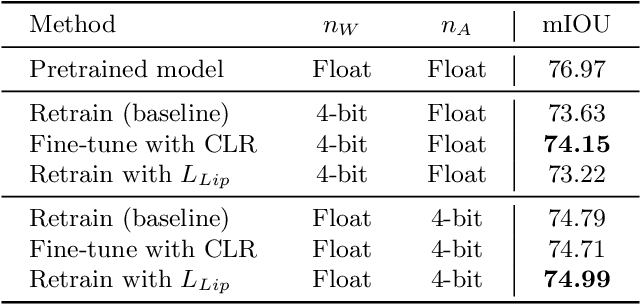
Quantized deep neural networks (QDNNs) are necessary for low-power, high throughput, and embedded applications. Previous studies mostly focused on developing optimization methods for the quantization of given models. However, quantization sensitivity depends on the model architecture. Therefore, the model selection needs to be a part of the QDNN design process. Also, the characteristics of weight and activation quantization are quite different. This study proposes a holistic approach for the optimization of QDNNs, which contains QDNN training methods as well as quantization-friendly architecture design. Synthesized data is used to visualize the effects of weight and activation quantization. The results indicate that deeper models are more prone to activation quantization, while wider models improve the resiliency to both weight and activation quantization. This study can provide insight into better optimization of QDNNs.