 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantity vs Quality: Investigating the Trade-Off between Sample Size and Label Reliability
Paper and Code
Apr 20, 2022
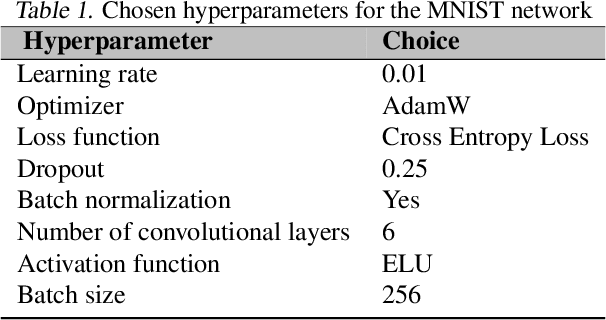

In this paper, we study learning in probabilistic domains where the learner may receive incorrect labels but can improve the reliability of labels by repeatedly sampling them. In such a setting, one faces the problem of whether the fixed budget for obtaining training examples should rather be used for obtaining all different examples or for improving the label quality of a smaller number of examples by re-sampling their labels. We motivate this problem in an application to compare the strength of poker hands where the training signal depends on the hidden community cards, and then study it in depth in an artificial setting where we insert controlled noise levels into the MNIST database. Our results show that with increasing levels of noise, resampling previous examples becomes increasingly more important than obtaining new examples, as classifier performance deteriorates when the number of incorrect labels is too high. In addition, we propose two different validation strategies; switching from lower to higher validations over the course of training and using chi-square statistics to approximate the confidence in obtained labels.