Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantitative stability of optimal transport maps and linearization of the 2-Wasserstein space
Paper and Code


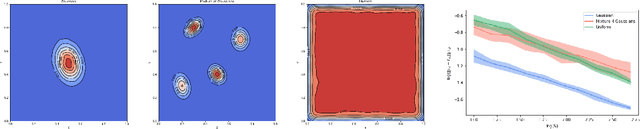

This work studies an explicit embedding of the set of probability measures into a Hilbert space, defined using optimal transport maps from a reference probability density. This embedding linearizes to some extent the 2-Wasserstein space, and enables the direct use of generic supervised and unsupervised learning algorithms on measure data. Our main result is that the embedding is (bi-)H\"older continuous, when the reference density is uniform over a convex set, and can be equivalently phrased as a dimension-independent H\"older-stability results for optimal transport maps.
* 21 pages
View paper on