 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantile Regression for Large-scale Applications
Paper and Code
Jan 07, 2014
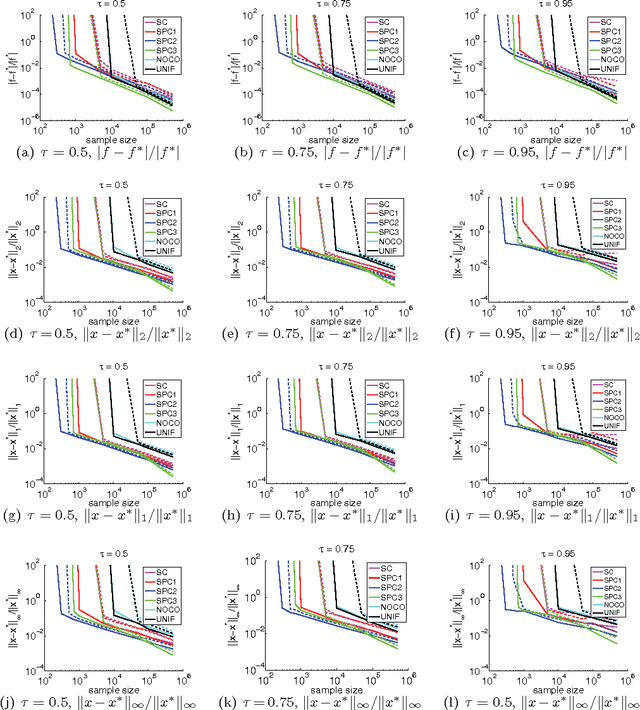
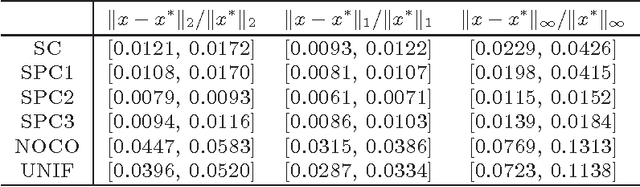
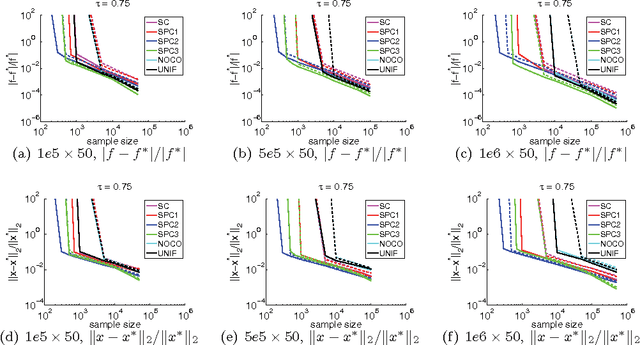
Quantile regression is a method to estimate the quantiles of the conditional distribution of a response variable, and as such it permits a much more accurate portrayal of the relationship between the response variable and observed covariates than methods such as Least-squares or Least Absolute Deviations regression. It can be expressed as a linear program, and, with appropriate preprocessing, interior-point methods can be used to find a solution for moderately large problems. Dealing with very large problems, \emph(e.g.), involving data up to and beyond the terabyte regime, remains a challenge. Here, we present a randomized algorithm that runs in nearly linear time in the size of the input and that, with constant probability, computes a $(1+\epsilon)$ approximate solution to an arbitrary quantile regression problem. As a key step, our algorithm computes a low-distortion subspace-preserving embedding with respect to the loss function of quantile regression. Our empirical evaluation illustrates that our algorithm is competitive with the best previous work on small to medium-sized problems, and that in addition it can be implemented in MapReduce-like environments and applied to terabyte-sized problems.