 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying the Impact of Data Characteristics on the Transferability of Sleep Stage Scoring Models
Paper and Code

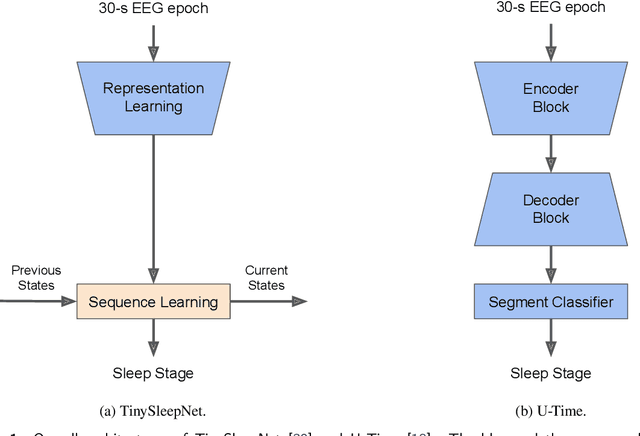
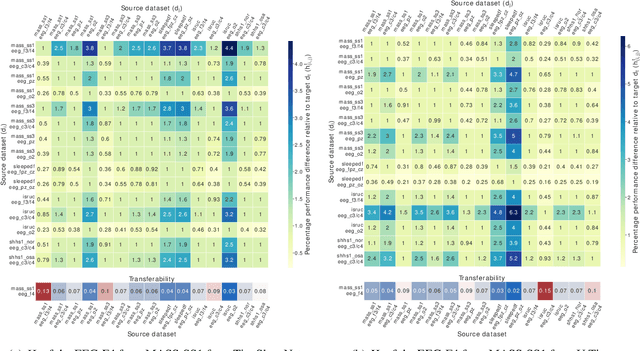
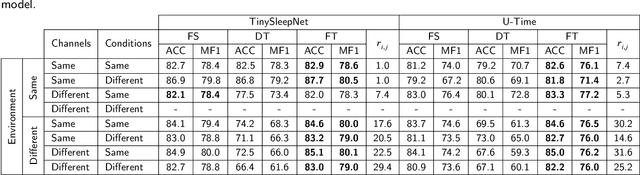
Deep learning models for scoring sleep stages based on single-channel EEG have been proposed as a promising method for remote sleep monitoring. However, applying these models to new datasets, particularly from wearable devices, raises two questions. First, when annotations on a target dataset are unavailable, which different data characteristics affect the sleep stage scoring performance the most and by how much? Second, when annotations are available, which dataset should be used as the source of transfer learning to optimize performance? In this paper, we propose a novel method for computationally quantifying the impact of different data characteristics on the transferability of deep learning models. Quantification is accomplished by training and evaluating two models with significant architectural differences, TinySleepNet and U-Time, under various transfer configurations in which the source and target datasets have different recording channels, recording environments, and subject conditions. For the first question, the environment had the highest impact on sleep stage scoring performance, with performance degrading by over 14% when sleep annotations were unavailable. For the second question, the most useful transfer sources for TinySleepNet and the U-Time models were MASS-SS1 and ISRUC-SG1, containing a high percentage of N1 (the rarest sleep stage) relative to the others. The frontal and central EEGs were preferred for TinySleepNet. The proposed approach enables full utilization of existing sleep datasets for training and planning model transfer to maximize the sleep stage scoring performance on a target problem when sleep annotations are limited or unavailable, supporting the realization of remote sleep monitoring.