 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQUACK: Quantum Aligned Centroid Kernel
Paper and Code
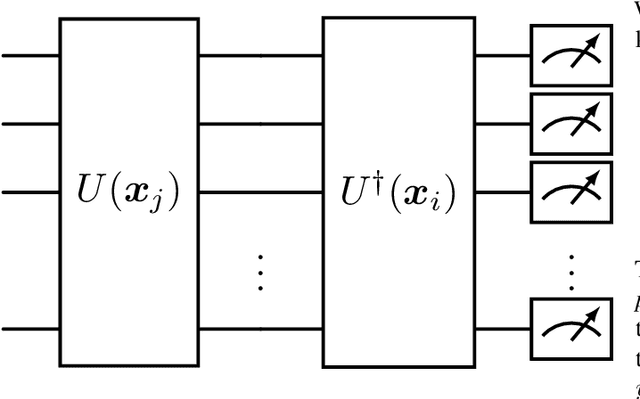


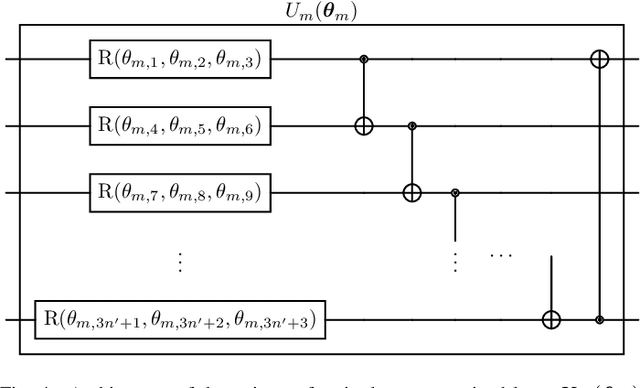
Quantum computing (QC) seems to show potential for application in machine learning (ML). In particular quantum kernel methods (QKM) exhibit promising properties for use in supervised ML tasks. However, a major disadvantage of kernel methods is their unfavorable quadratic scaling with the number of training samples. Together with the limits imposed by currently available quantum hardware (NISQ devices) with their low qubit coherence times, small number of qubits, and high error rates, the use of QC in ML at an industrially relevant scale is currently impossible. As a small step in improving the potential applications of QKMs, we introduce QUACK, a quantum kernel algorithm whose time complexity scales linear with the number of samples during training, and independent of the number of training samples in the inference stage. In the training process, only the kernel entries for the samples and the centers of the classes are calculated, i.e. the maximum shape of the kernel for n samples and c classes is (n, c). During training, the parameters of the quantum kernel and the positions of the centroids are optimized iteratively. In the inference stage, for every new sample the circuit is only evaluated for every centroid, i.e. c times. We show that the QUACK algorithm nevertheless provides satisfactory results and can perform at a similar level as classical kernel methods with quadratic scaling during training. In addition, our (simulated) algorithm is able to handle high-dimensional datasets such as MNIST with 784 features without any dimensionality reduction.