 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePushing the Limits of Asynchronous Graph-based Object Detection with Event Cameras
Paper and Code
Nov 22, 2022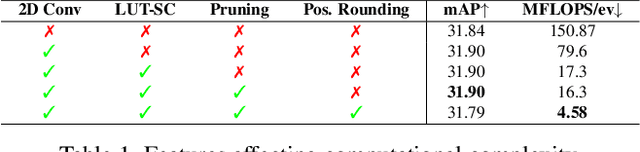
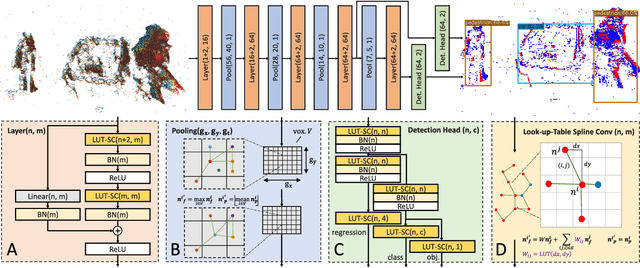
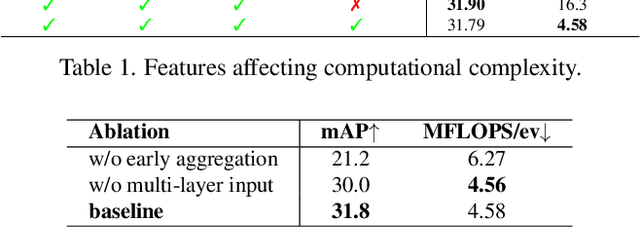

State-of-the-art machine-learning methods for event cameras treat events as dense representations and process them with conventional deep neural networks. Thus, they fail to maintain the sparsity and asynchronous nature of event data, thereby imposing significant computation and latency constraints on downstream systems. A recent line of work tackles this issue by modeling events as spatiotemporally evolving graphs that can be efficiently and asynchronously processed using graph neural networks. These works showed impressive computation reductions, yet their accuracy is still limited by the small scale and shallow depth of their network, both of which are required to reduce computation. In this work, we break this glass ceiling by introducing several architecture choices which allow us to scale the depth and complexity of such models while maintaining low computation. On object detection tasks, our smallest model shows up to 3.7 times lower computation, while outperforming state-of-the-art asynchronous methods by 7.4 mAP. Even when scaling to larger model sizes, we are 13% more efficient than state-of-the-art while outperforming it by 11.5 mAP. As a result, our method runs 3.7 times faster than a dense graph neural network, taking only 8.4 ms per forward pass. This opens the door to efficient, and accurate object detection in edge-case scenarios.