 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePSG: Prompt-based Sequence Generation for Acronym Extraction
Paper and Code


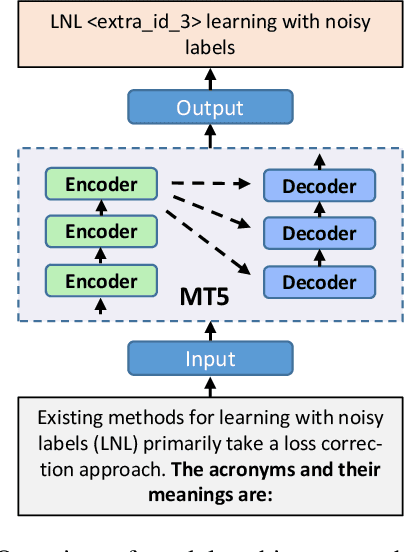
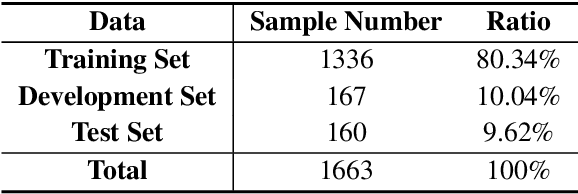
Acronym extraction aims to find acronyms (i.e., short-forms) and their meanings (i.e., long-forms) from the documents, which is important for scientific document understanding (SDU@AAAI-22) tasks. Previous works are devoted to modeling this task as a paragraph-level sequence labeling problem. However, it lacks the effective use of the external knowledge, especially when the datasets are in a low-resource setting. Recently, the prompt-based method with the vast pre-trained language model can significantly enhance the performance of the low-resourced downstream tasks. In this paper, we propose a Prompt-based Sequence Generation (PSG) method for the acronym extraction task. Specifically, we design a template for prompting the extracted acronym texts with auto-regression. A position extraction algorithm is designed for extracting the position of the generated answers. The results on the acronym extraction of Vietnamese and Persian in a low-resource setting show that the proposed method outperforms all other competitive state-of-the-art (SOTA) methods.