Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePruning Early Exit Networks
Paper and Code
Jul 08, 2022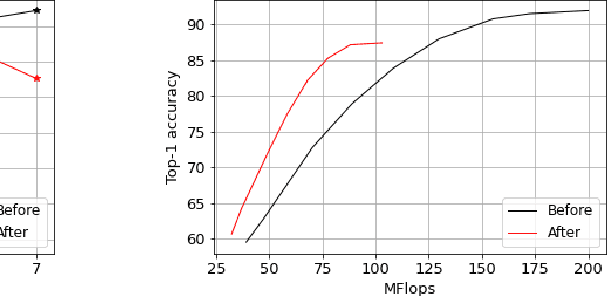
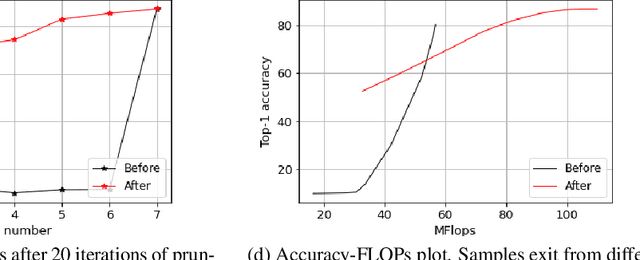
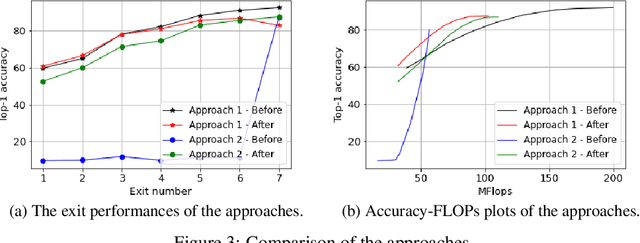
Deep learning models that perform well often have high computational costs. In this paper, we combine two approaches that try to reduce the computational cost while keeping the model performance high: pruning and early exit networks. We evaluate two approaches of pruning early exit networks: (1) pruning the entire network at once, (2) pruning the base network and additional linear classifiers in an ordered fashion. Experimental results show that pruning the entire network at once is a better strategy in general. However, at high accuracy rates, the two approaches have a similar performance, which implies that the processes of pruning and early exit can be separated without loss of optimality.
* 5 pages, 3 figures, Sparsity in Neural Networks Workshop 2022
View paper on