Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePruning and Quantization for Deep Neural Network Acceleration: A Survey
Paper and Code
Jan 24, 2021
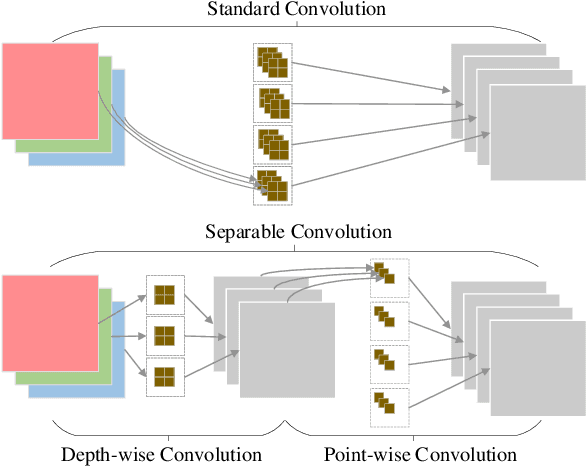
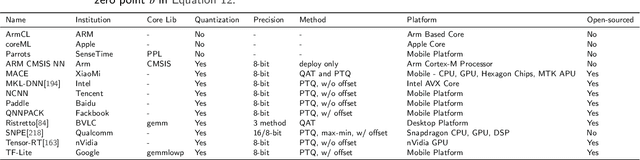
Deep neural networks have been applied in many applications exhibiting extraordinary abilities in the field of computer vision. However, complex network architectures challenge efficient real-time deployment and require significant computation resources and energy costs. These challenges can be overcome through optimizations such as network compression. This paper provides a survey on two types of network compression: pruning and quantization. We compare current techniques, analyze their strengths and weaknesses, provide guidance for compressing networks, and discuss possible future compression techniques.
View paper on