 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProximal Reinforcement Learning: Efficient Off-Policy Evaluation in Partially Observed Markov Decision Processes
Paper and Code
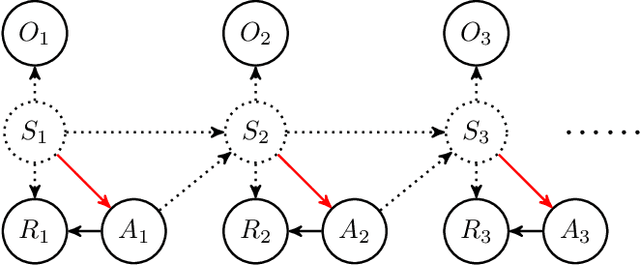
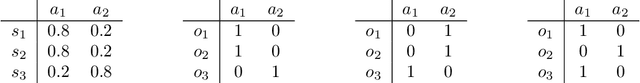
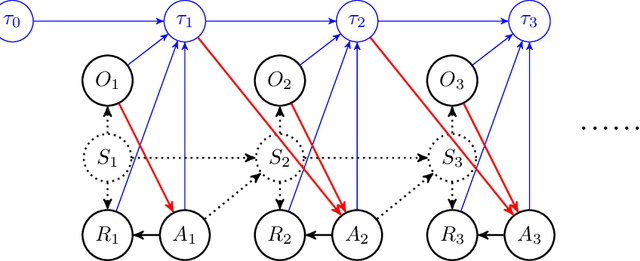
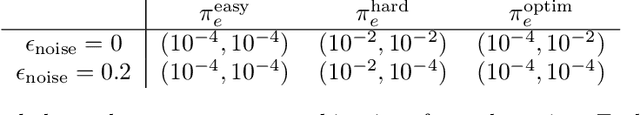
In applications of offline reinforcement learning to observational data, such as in healthcare or education, a general concern is that observed actions might be affected by unobserved factors, inducing confounding and biasing estimates derived under the assumption of a perfect Markov decision process (MDP) model. Here we tackle this by considering off-policy evaluation in a partially observed MDP (POMDP). Specifically, we consider estimating the value of a given target policy in a POMDP given trajectories with only partial state observations generated by a different and unknown policy that may depend on the unobserved state. We tackle two questions: what conditions allow us to identify the target policy value from the observed data and, given identification, how to best estimate it. To answer these, we extend the framework of proximal causal inference to our POMDP setting, providing a variety of settings where identification is made possible by the existence of so-called bridge functions. We then show how to construct semiparametrically efficient estimators in these settings. We term the resulting framework proximal reinforcement learning (PRL). We demonstrate the benefits of PRL in an extensive simulation study.