 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProximal Distilled Evolutionary Reinforcement Learning
Paper and Code
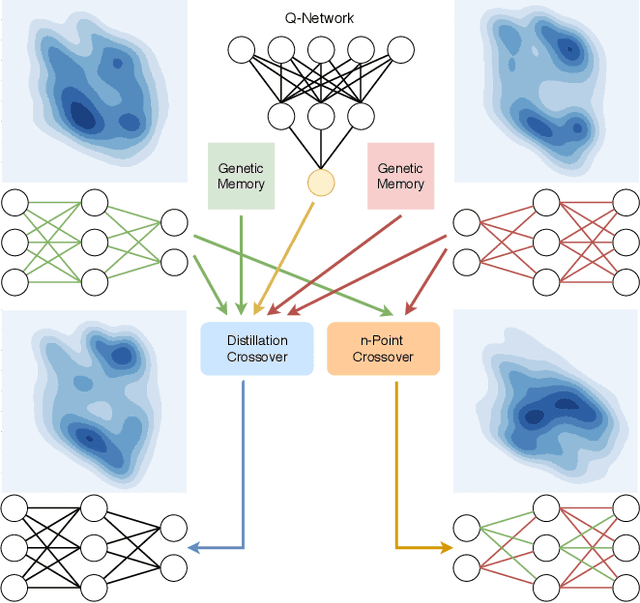

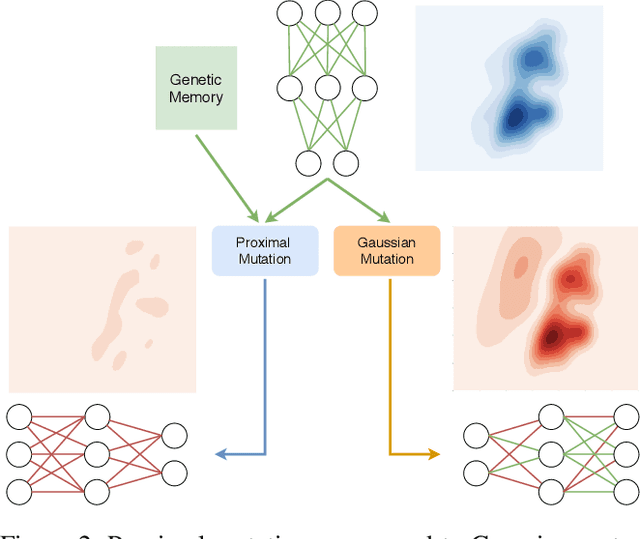

Reinforcement Learning (RL) has recently achieved tremendous success due to the partnership with Deep Neural Networks (DNNs). Genetic Algorithms (GAs), often seen as a competing approach to RL, have run out of favour due to their inability to scale up to the DNNs required to solve the most complex environments. Contrary to this dichotomic view, in the physical world, evolution and learning are complementary processes that continuously interact. The recently proposed Evolutionary Reinforcement Learning (ERL) framework has demonstrated the capacity of the two methods to enhance each other. However, ERL has not fully addressed the scalability problem of GAs. In this paper, we argue that this problem is rooted in an unfortunate combination of a simple genetic encoding for DNNs and the use of traditional biologically-inspired variation operators. When applied to these encodings, the standard operators are destructive and cause catastrophic forgetting of the traits the networks acquired. We propose a novel algorithm called Proximal Distilled Evolutionary Reinforcement Learning (PDERL) that is characterised by a hierarchical integration between evolution and learning. The main innovation of PDERL is the use of learning-based variation operators that compensate for the simplicity of the genetic representation. Unlike the traditional operators, the ones we propose meet their functional requirements. We evaluate PDERL in five robot locomotion environments from the OpenAI gym. Our method outperforms ERL, as well as two state of the art RL algorithms, PPO and TD3, in all the environments.