 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProving Non-Inclusion of Büchi Automata based on Monte Carlo Sampling
Paper and Code
Jul 07, 2020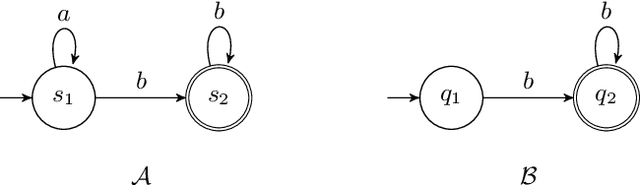
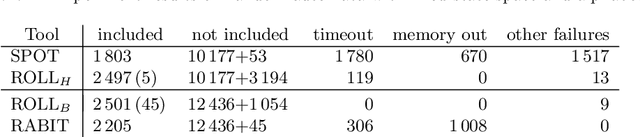
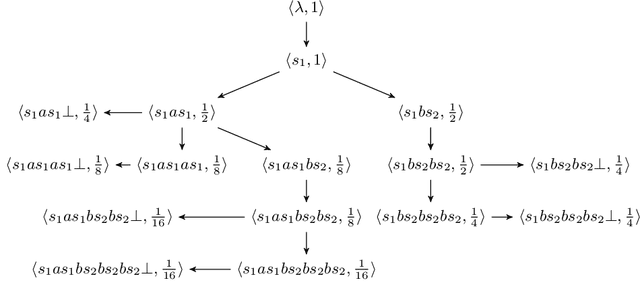
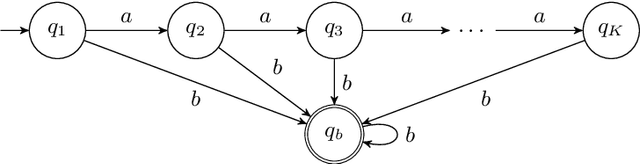
The search for a proof of correctness and the search for counterexamples (bugs) are complementary aspects of verification. In order to maximize the practical use of verification tools it is better to pursue them at the same time. While this is well-understood in the termination analysis of programs, this is not the case for the language inclusion analysis of B\"uchi automata, where research mainly focused on improving algorithms for proving language inclusion, with the search for counterexamples left to the expensive complementation operation. In this paper, we present $\mathsf{IMC}^2$, a specific algorithm for proving B\"uchi automata non-inclusion $\mathcal{L}(\mathcal{A}) \not\subseteq \mathcal{L}(\mathcal{B})$, based on Grosu and Smolka's algorithm $\mathsf{MC}^2$ developed for Monte Carlo model checking against LTL formulas. The algorithm we propose takes $M = \lceil \ln \delta / \ln (1-\epsilon) \rceil$ random lasso-shaped samples from $\mathcal{A}$ to decide whether to reject the hypothesis $\mathcal{L}(\mathcal{A}) \not\subseteq \mathcal{L}(\mathcal{B})$, for given error probability $\epsilon$ and confidence level $1 - \delta$. With such a number of samples, $\mathsf{IMC}^2$ ensures that the probability of witnessing $\mathcal{L}(\mathcal{A}) \not\subseteq \mathcal{L}(\mathcal{B})$ via further sampling is less than $\delta$, under the assumption that the probability of finding a lasso counterexample is larger than $\epsilon$. Extensive experimental evaluation shows that $\mathsf{IMC}^2$ is a fast and reliable way to find counterexamples to B\"uchi automata inclusion.