 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvably Efficient Exploration in Inverse Constrained Reinforcement Learning
Paper and Code
Sep 24, 2024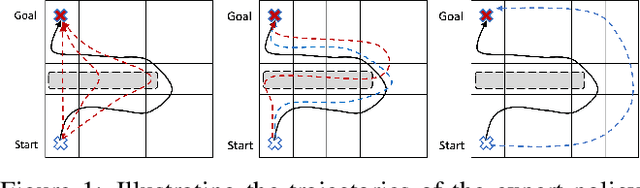
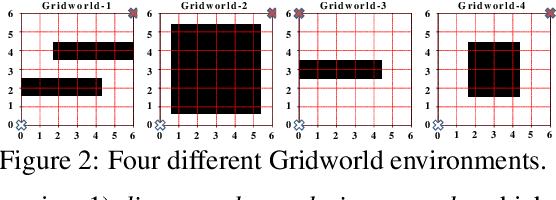
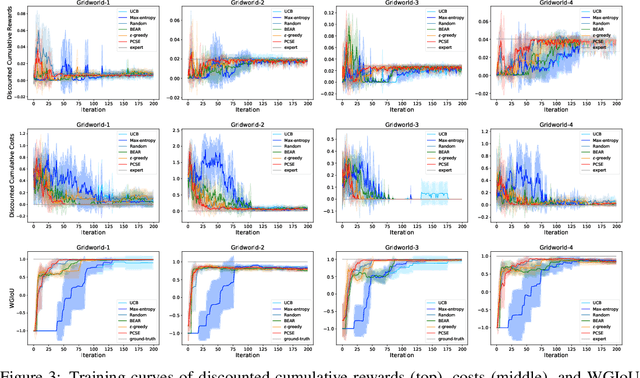
To obtain the optimal constraints in complex environments, Inverse Constrained Reinforcement Learning (ICRL) seeks to recover these constraints from expert demonstrations in a data-driven manner. Existing ICRL algorithms collect training samples from an interactive environment. However, the efficacy and efficiency of these sampling strategies remain unknown. To bridge this gap, we introduce a strategic exploration framework with provable efficiency. Specifically, we define a feasible constraint set for ICRL problems and investigate how expert policy and environmental dynamics influence the optimality of constraints. Motivated by our findings, we propose two exploratory algorithms to achieve efficient constraint inference via 1) dynamically reducing the bounded aggregate error of cost estimation and 2) strategically constraining the exploration policy. Both algorithms are theoretically grounded with tractable sample complexity. We empirically demonstrate the performance of our algorithms under various environments.