 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvable Hierarchical Imitation Learning via EM
Paper and Code
Oct 07, 2020
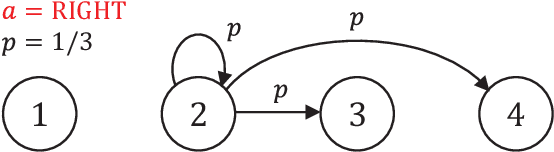
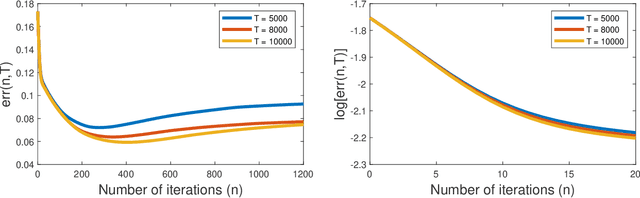
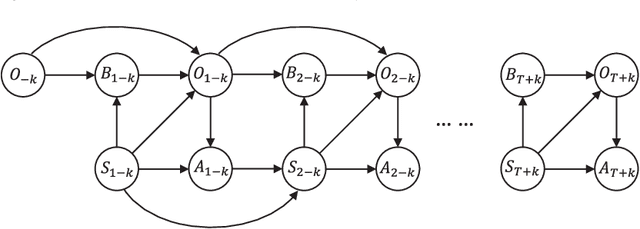
Due to recent empirical successes, the options framework for hierarchical reinforcement learning is gaining increasing popularity. Rather than learning from rewards which suffers from the curse of dimensionality, we consider learning an options-type hierarchical policy from expert demonstrations. Such a problem is referred to as hierarchical imitation learning. Converting this problem to parameter inference in a latent variable model, we theoretically characterize the EM approach proposed by Daniel et al. (2016). The population level algorithm is analyzed as an intermediate step, which is nontrivial due to the samples being correlated. If the expert policy can be parameterized by a variant of the options framework, then under regularity conditions, we prove that the proposed algorithm converges with high probability to a norm ball around the true parameter. To our knowledge, this is the first performance guarantee for an hierarchical imitation learning algorithm that only observes primitive state-action pairs.