 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvable concept learning for interpretable predictions using variational inference
Paper and Code

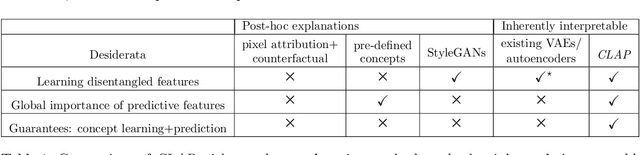
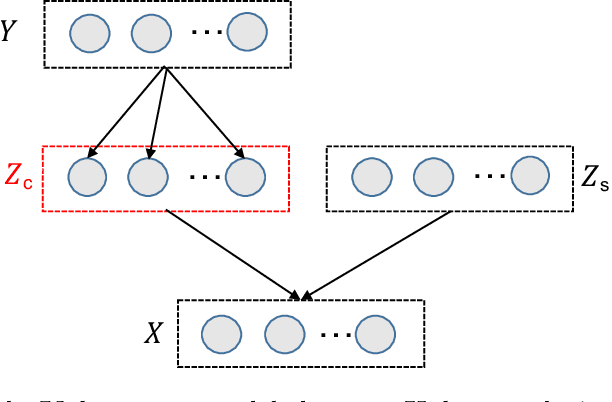
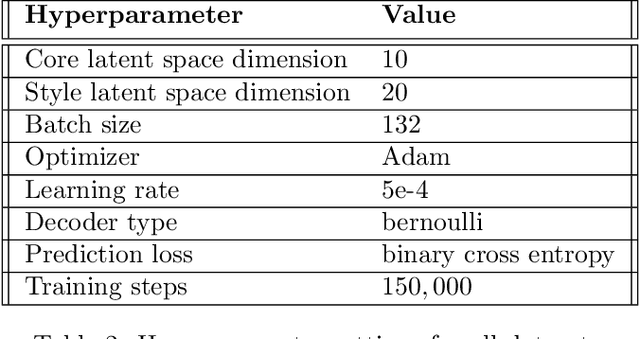
In safety critical applications, practitioners are reluctant to trust neural networks when no interpretable explanations are available. Many attempts to provide such explanations revolve around pixel level attributions or use previously known concepts. In this paper we aim to provide explanations by provably identifying \emph{high-level, previously unknown concepts}. To this end, we propose a probabilistic modeling framework to derive (C)oncept (L)earning and (P)rediction (CLAP) -- a VAE-based classifier that uses visually interpretable concepts as linear predictors. Assuming that the data generating mechanism involves predictive concepts, we prove that our method is able to identify them while attaining optimal classification accuracy. We use synthetic experiments for validation, and also show that on real-world (PlantVillage and ChestXRay) datasets, CLAP effectively discovers interpretable factors for classifying diseases.