 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProSelfLC: Progressive Self Label Correction for Training Robust Deep Neural Networks
Paper and Code
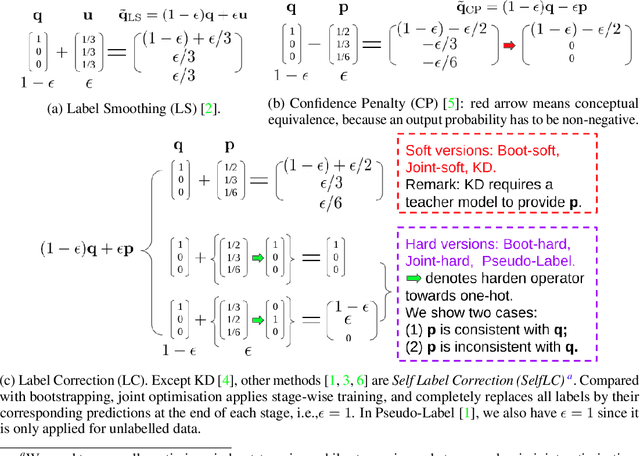

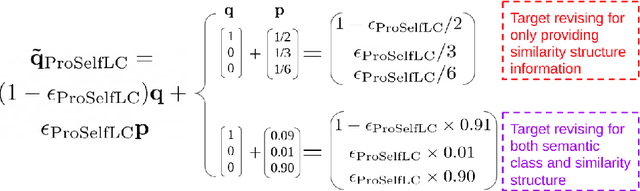
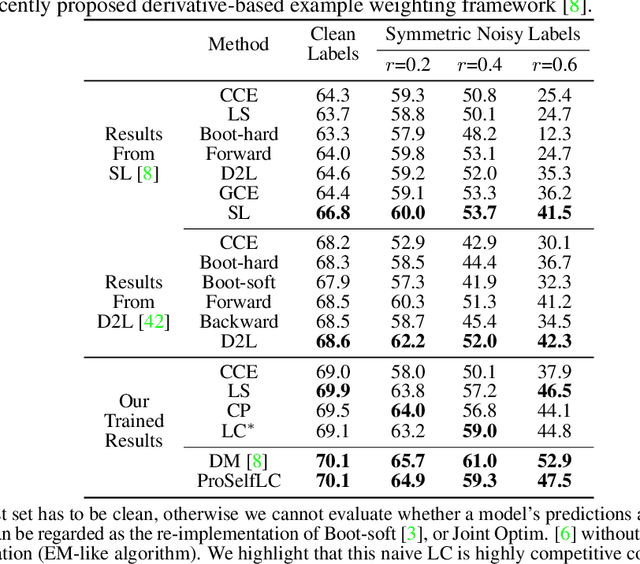
We systematically study popular target modification approaches in supervised learning. We show that they can be connected mathematically through entropy and KL divergence. This uncovers that some methods penalise while the others reward low entropy. Additionally, some of them are suboptimal because they do not leverage the knowledge of a model itself; some rely on extra learners or stage-wise training that may require a human intervention thus being difficult to optimise; most importantly, there does not exist an automatic way to decide how much we trust a predicted label distribution, let alone exploiting it. To resolve these issues, taking two well-accepted expertise: deep neural networks learn meaningful patterns before fitting noise [1] and minimum entropy regularisation principle [2], we propose a simple end-to-end method named ProSelfLC, which is endorsed by long learning time and high prediction confidence. Specifically, given a data point, we progressively trust more its predicted label distribution than its annotated one if a model has been trained for a long time and outputs a highly confident prediction (low entropy). By extensive experiments, we show: (1) ProSelfLC can revise an example's one-hot label distribution by adding the perceptual similarity structure information so that its learning target becomes structured and soft; (2) When being applied to noisy labels, it can correct their semantic classes; (3) It outperforms existing methods with the lowest entropy, which indicates it is right for a learner to be confident in correct patterns.