 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProMix: Combating Label Noise via Maximizing Clean Sample Utility
Paper and Code

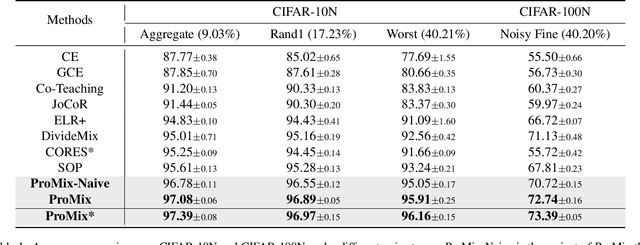
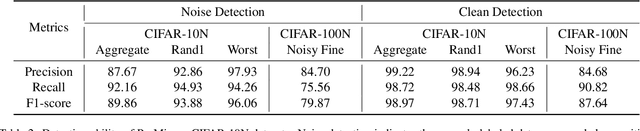
The ability to train deep neural networks under label noise is appealing, as imperfectly annotated data are relatively cheaper to obtain. State-of-the-art approaches are based on semi-supervised learning(SSL), which selects small loss examples as clean and then applies SSL techniques for boosted performance. However, the selection step mostly provides a medium-sized and decent-enough clean subset, which overlooks a rich set of clean samples. In this work, we propose a novel noisy label learning framework ProMix that attempts to maximize the utility of clean samples for boosted performance. Key to our method, we propose a matched high-confidence selection technique that selects those examples having high confidence and matched prediction with its given labels. Combining with the small-loss selection, our method is able to achieve a precision of 99.27 and a recall of 98.22 in detecting clean samples on the CIFAR-10N dataset. Based on such a large set of clean data, ProMix improves the best baseline method by +2.67% on CIFAR-10N and +1.61% on CIFAR-100N datasets. The code and data are available at https://github.com/Justherozen/ProMix