 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProLex: A Benchmark for Language Proficiency-oriented Lexical Substitution
Paper and Code
Jan 21, 2024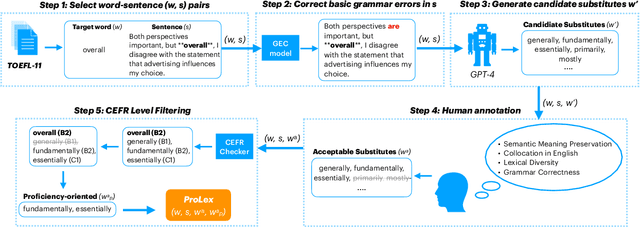
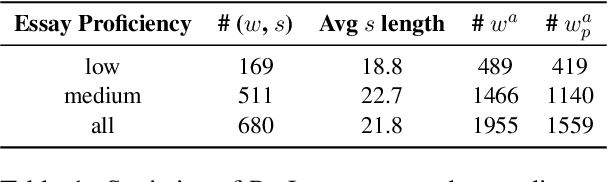
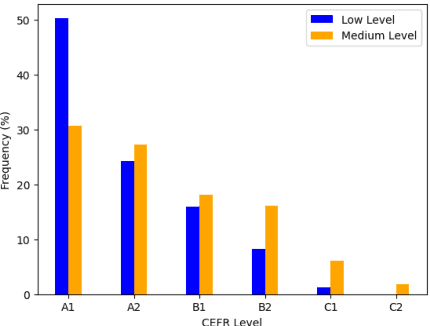

Lexical Substitution discovers appropriate substitutes for a given target word in a context sentence. However, the task fails to consider substitutes that are of equal or higher proficiency than the target, an aspect that could be beneficial for language learners looking to improve their writing. To bridge this gap, we propose a new task, language proficiency-oriented lexical substitution. We also introduce ProLex, a novel benchmark designed to assess systems' ability to generate not only appropriate substitutes but also substitutes that demonstrate better language proficiency. Besides the benchmark, we propose models that can automatically perform the new task. We show that our best model, a Llama2-13B model fine-tuned with task-specific synthetic data, outperforms ChatGPT by an average of 3.2% in F-score and achieves comparable results with GPT-4 on ProLex.