 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgressive Joint Modeling in Unsupervised Single-channel Overlapped Speech Recognition
Paper and Code
Oct 20, 2017
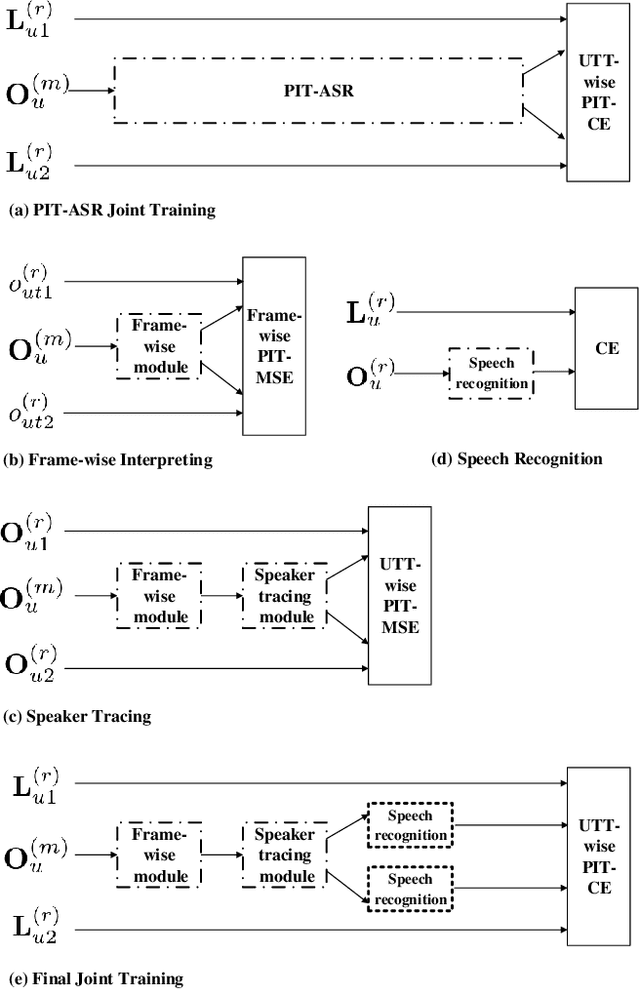

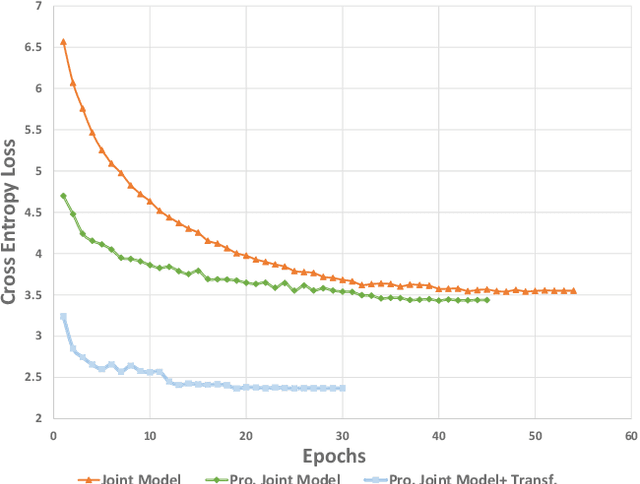
Unsupervised single-channel overlapped speech recognition is one of the hardest problems in automatic speech recognition (ASR). Permutation invariant training (PIT) is a state of the art model-based approach, which applies a single neural network to solve this single-input, multiple-output modeling problem. We propose to advance the current state of the art by imposing a modular structure on the neural network, applying a progressive pretraining regimen, and improving the objective function with transfer learning and a discriminative training criterion. The modular structure splits the problem into three sub-tasks: frame-wise interpreting, utterance-level speaker tracing, and speech recognition. The pretraining regimen uses these modules to solve progressively harder tasks. Transfer learning leverages parallel clean speech to improve the training targets for the network. Our discriminative training formulation is a modification of standard formulations, that also penalizes competing outputs of the system. Experiments are conducted on the artificial overlapped Switchboard and hub5e-swb dataset. The proposed framework achieves over 30% relative improvement of WER over both a strong jointly trained system, PIT for ASR, and a separately optimized system, PIT for speech separation with clean speech ASR model. The improvement comes from better model generalization, training efficiency and the sequence level linguistic knowledge integration.