 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProduction vs Perception: The Role of Individuality in Usage-Based Grammar Induction
Paper and Code

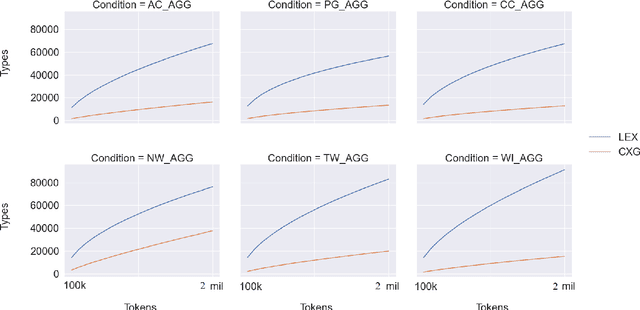
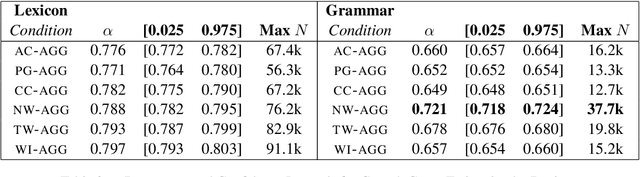
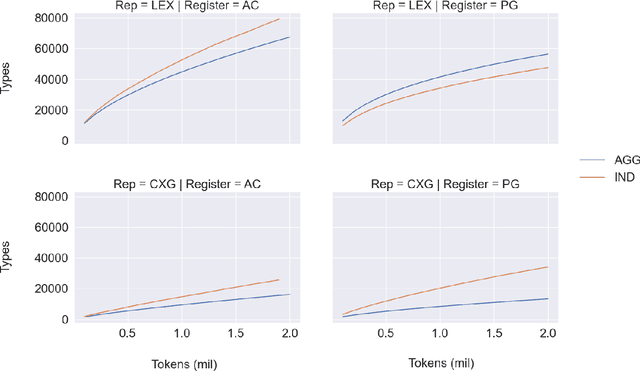
This paper asks whether a distinction between production-based and perception-based grammar induction influences either (i) the growth curve of grammars and lexicons or (ii) the similarity between representations learned from independent sub-sets of a corpus. A production-based model is trained on the usage of a single individual, thus simulating the grammatical knowledge of a single speaker. A perception-based model is trained on an aggregation of many individuals, thus simulating grammatical generalizations learned from exposure to many different speakers. To ensure robustness, the experiments are replicated across two registers of written English, with four additional registers reserved as a control. A set of three computational experiments shows that production-based grammars are significantly different from perception-based grammars across all conditions, with a steeper growth curve that can be explained by substantial inter-individual grammatical differences.