 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Frame Induction
Paper and Code
Feb 20, 2013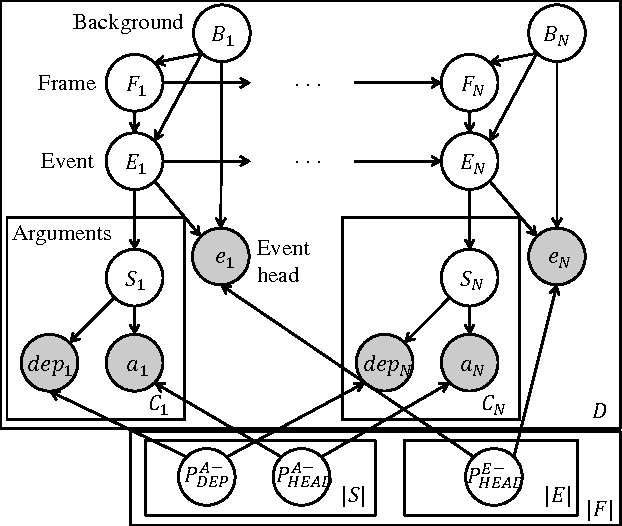
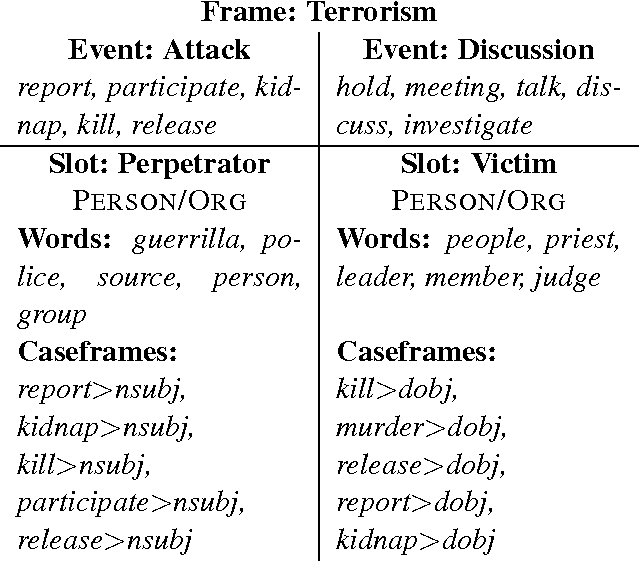
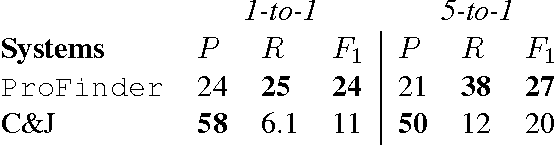
In natural-language discourse, related events tend to appear near each other to describe a larger scenario. Such structures can be formalized by the notion of a frame (a.k.a. template), which comprises a set of related events and prototypical participants and event transitions. Identifying frames is a prerequisite for information extraction and natural language generation, and is usually done manually. Methods for inducing frames have been proposed recently, but they typically use ad hoc procedures and are difficult to diagnose or extend. In this paper, we propose the first probabilistic approach to frame induction, which incorporates frames, events, participants as latent topics and learns those frame and event transitions that best explain the text. The number of frames is inferred by a novel application of a split-merge method from syntactic parsing. In end-to-end evaluations from text to induced frames and extracted facts, our method produced state-of-the-art results while substantially reducing engineering effort.