 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic bounds on data sensitivity in deep rectifier networks
Paper and Code
Jul 13, 2020
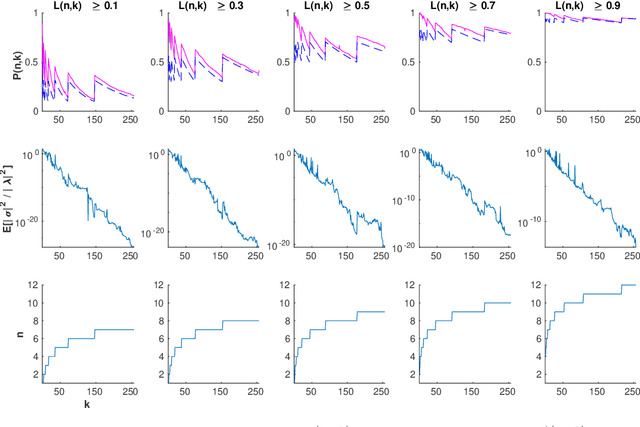
Neuron death is a complex phenomenon with implications for model trainability, but until recently it was measured only empirically. Recent articles have claimed that, as the depth of a rectifier neural network grows to infinity, the probability of finding a valid initialization decreases to zero. In this work, we provide a simple and rigorous proof of that result. Then, we show what happens when the width of each layer grows simultaneously with the depth. We derive both upper and lower bounds on the probability that a ReLU network is initialized to a trainable point, as a function of model hyperparameters. Contrary to previous claims, we show that it is possible to increase the depth of a network indefinitely, so long as the width increases as well. Furthermore, our bounds are asymptotically tight under reasonable assumptions: first, the upper bound coincides with the true probability for a single-layer network with the largest possible input set. Second, the true probability converges to our lower bound when the network width and depth both grow without limit. Our proof is based on the striking observation that very deep rectifier networks concentrate all outputs towards a single eigenvalue, in the sense that their normalized output variance goes to zero regardless of the network width. Finally, we develop a practical sign flipping scheme which guarantees with probability one that for a $k$-layer network, the ratio of living training data points is at least $2^{-k}$. We confirm our results with numerical simulations, suggesting that the actual improvement far exceeds the theoretical minimum. We also discuss how neuron death provides a theoretical interpretation for various network design choices such as batch normalization, residual layers and skip connections, and could inform the design of very deep neural networks.