Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreventing Adversarial Use of Datasets through Fair Core-Set Construction
Paper and Code
Oct 24, 2019
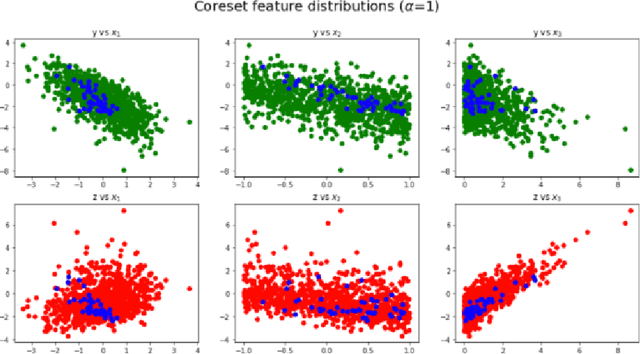
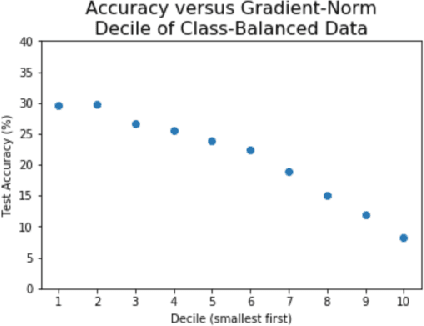
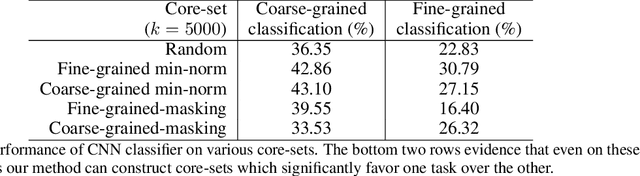
We propose improving the privacy properties of a dataset by publishing only a strategically chosen "core-set" of the data containing a subset of the instances. The core-set allows strong performance on primary tasks, but forces poor performance on unwanted tasks. We give methods for both linear models and neural networks and demonstrate their efficacy on data.
* 6 pages, 2 figures, NeurIPS 2019 Privacy In Machine Learning Workshop
(PriML 2019)
View paper on