 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictive Coarse-Graining
Paper and Code
Sep 28, 2016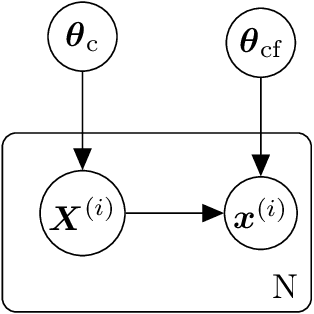
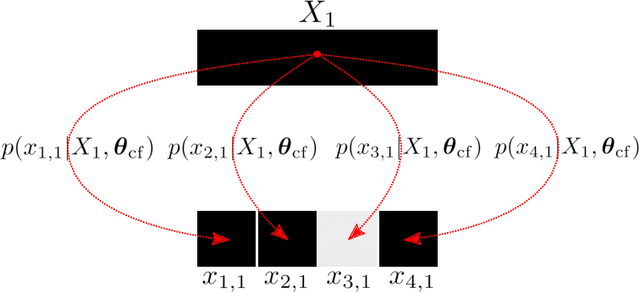
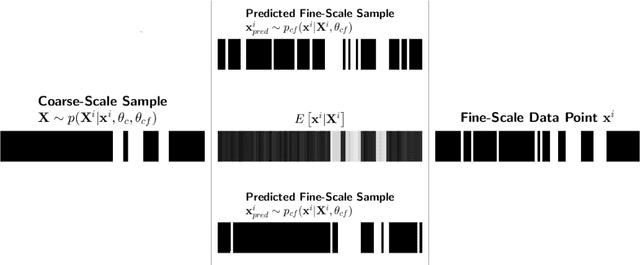
We propose a data-driven, coarse-graining formulation in the context of equilibrium statistical mechanics. In contrast to existing techniques which are based on a fine-to-coarse map, we adopt the opposite strategy by prescribing a probabilistic coarse-to-fine map. This corresponds to a directed probabilistic model where the coarse variables play the role of latent generators of the fine scale (all-atom) data. From an information-theoretic perspective, the framework proposed provides an improvement upon the relative entropy method and is capable of quantifying the uncertainty due to the information loss that unavoidably takes place during the CG process. Furthermore, it can be readily extended to a fully Bayesian model where various sources of uncertainties are reflected in the posterior of the model parameters. The latter can be used to produce not only point estimates of fine-scale reconstructions or macroscopic observables, but more importantly, predictive posterior distributions on these quantities. Predictive posterior distributions reflect the confidence of the model as a function of the amount of data and the level of coarse-graining. The issues of model complexity and model selection are seamlessly addressed by employing a hierarchical prior that favors the discovery of sparse solutions, revealing the most prominent features in the coarse-grained model. A flexible and parallelizable Monte Carlo - Expectation-Maximization (MC-EM) scheme is proposed for carrying out inference and learning tasks. A comparative assessment of the proposed methodology is presented for a lattice spin system and the SPC/E water model.