 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictive Bandits
Paper and Code
Apr 02, 2020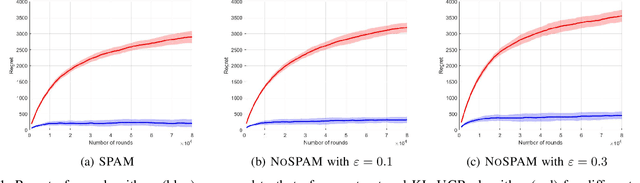

We introduce and study a new class of stochastic bandit problems, referred to as predictive bandits. In each round, the decision maker first decides whether to gather information about the rewards of particular arms (so that their rewards in this round can be predicted). These measurements are costly, and may be corrupted by noise. The decision maker then selects an arm to be actually played in the round. Predictive bandits find applications in many areas; e.g. they can be applied to channel selection problems in radio communication systems. In this paper, we provide the first theoretical results about predictive bandits, and focus on scenarios where the decision maker is allowed to measure at most one arm per round. We derive asymptotic instance-specific regret lower bounds for these problems, and develop algorithms whose regret match these fundamental limits. We illustrate the performance of our algorithms through numerical experiments. In particular, we highlight the gains that can be achieved by using reward predictions, and investigate the impact of the noise in the corresponding measurements.