 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting phoneme-level prosody latents using AR and flow-based Prior Networks for expressive speech synthesis
Paper and Code
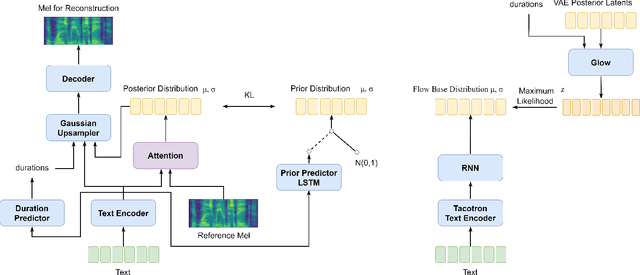
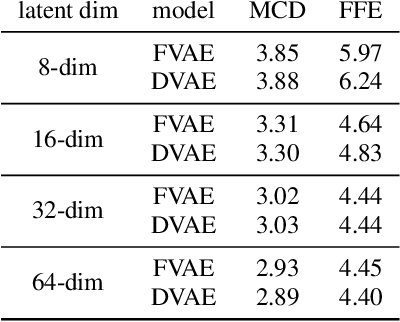
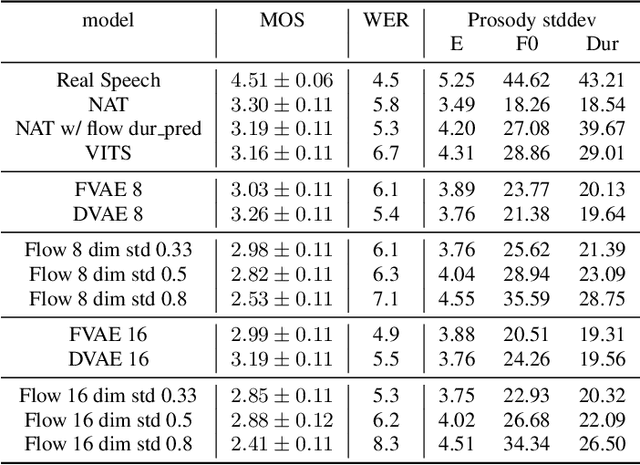
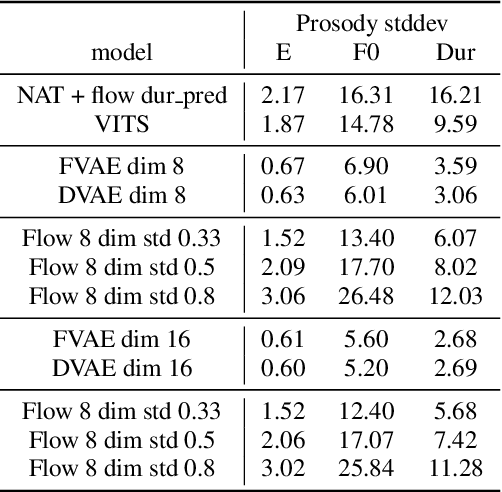
A large part of the expressive speech synthesis literature focuses on learning prosodic representations of the speech signal which are then modeled by a prior distribution during inference. In this paper, we compare different prior architectures at the task of predicting phoneme level prosodic representations extracted with an unsupervised FVAE model. We use both subjective and objective metrics to show that normalizing flow based prior networks can result in more expressive speech at the cost of a slight drop in quality. Furthermore, we show that the synthesized speech has higher variability, for a given text, due to the nature of normalizing flows. We also propose a Dynamical VAE model, that can generate higher quality speech although with decreased expressiveness and variability compared to the flow based models.