 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Adversarial Examples with High Confidence
Paper and Code
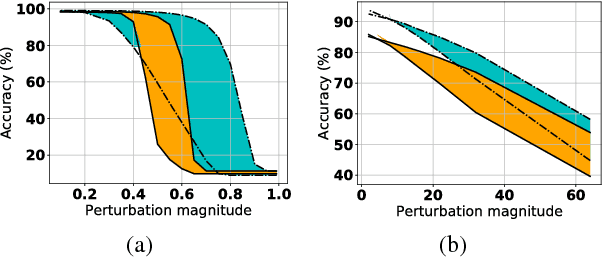
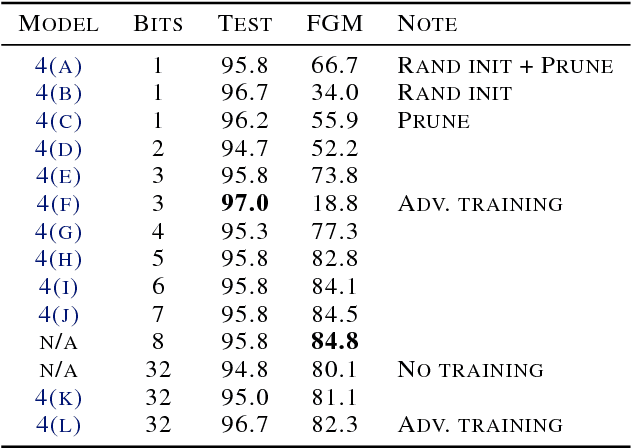

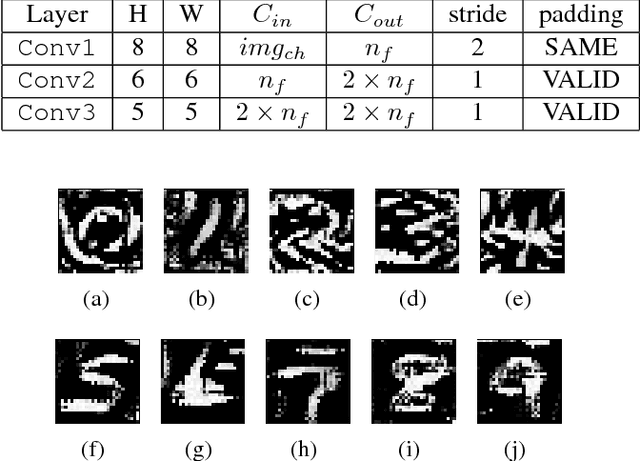
It has been suggested that adversarial examples cause deep learning models to make incorrect predictions with high confidence. In this work, we take the opposite stance: an overly confident model is more likely to be vulnerable to adversarial examples. This work is one of the most proactive approaches taken to date, as we link robustness with non-calibrated model confidence on noisy images, providing a data-augmentation-free path forward. The adversarial examples phenomenon is most easily explained by the trend of increasing non-regularized model capacity, while the diversity and number of samples in common datasets has remained flat. Test accuracy has incorrectly been associated with true generalization performance, ignoring that training and test splits are often extremely similar in terms of the overall representation space. The transferability property of adversarial examples was previously used as evidence against overfitting arguments, a perceived random effect, but overfitting is not always random.