 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-training transformer-based framework on large-scale pediatric claims data for downstream population-specific tasks
Paper and Code
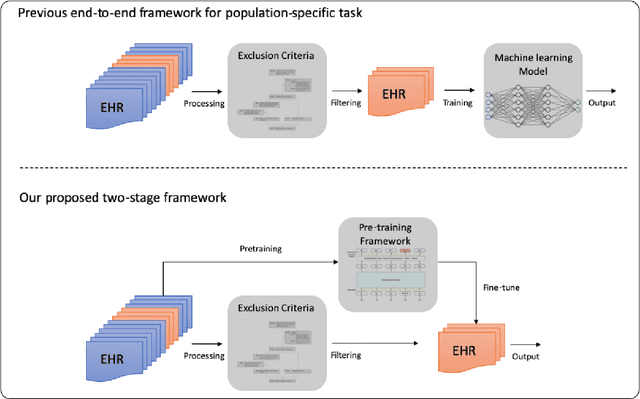
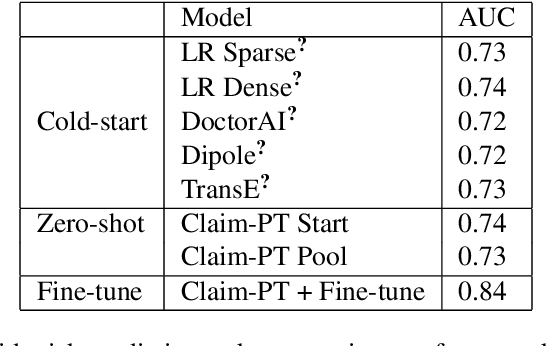
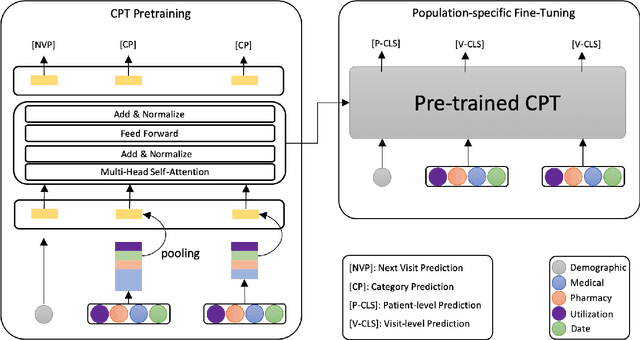
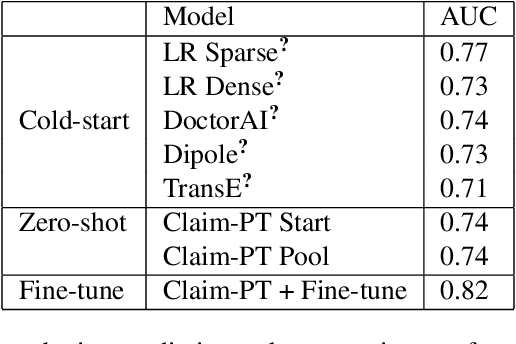
The adoption of electronic health records (EHR) has become universal during the past decade, which has afforded in-depth data-based research. By learning from the large amount of healthcare data, various data-driven models have been built to predict future events for different medical tasks, such as auto diagnosis and heart-attack prediction. Although EHR is abundant, the population that satisfies specific criteria for learning population-specific tasks is scarce, making it challenging to train data-hungry deep learning models. This study presents the Claim Pre-Training (Claim-PT) framework, a generic pre-training model that first trains on the entire pediatric claims dataset, followed by a discriminative fine-tuning on each population-specific task. The semantic meaning of medical events can be captured in the pre-training stage, and the effective knowledge transfer is completed through the task-aware fine-tuning stage. The fine-tuning process requires minimal parameter modification without changing the model architecture, which mitigates the data scarcity issue and helps train the deep learning model adequately on small patient cohorts. We conducted experiments on a real-world claims dataset with more than one million patient records. Experimental results on two downstream tasks demonstrated the effectiveness of our method: our general task-agnostic pre-training framework outperformed tailored task-specific models, achieving more than 10\% higher in model performance as compared to baselines. In addition, our framework showed a great generalizability potential to transfer learned knowledge from one institution to another, paving the way for future healthcare model pre-training across institutions.