 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-Training Multi-Modal Dense Retrievers for Outside-Knowledge Visual Question Answering
Paper and Code


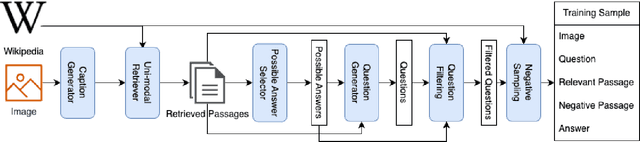
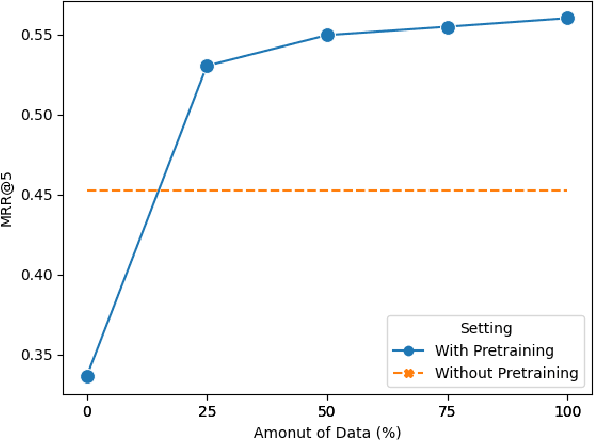
This paper studies a category of visual question answering tasks, in which accessing external knowledge is necessary for answering the questions. This category is called outside-knowledge visual question answering (OK-VQA). A major step in developing OK-VQA systems is to retrieve relevant documents for the given multi-modal query. Current state-of-the-art asymmetric dense retrieval model for this task uses an architecture with a multi-modal query encoder and a uni-modal document encoder. Such an architecture requires a large amount of training data for effective performance. We propose an automatic data generation pipeline for pre-training passage retrieval models for OK-VQA tasks. The proposed approach leads to 26.9% Precision@5 improvements compared to the current state-of-the-art asymmetric architecture. Additionally, the proposed pre-training approach exhibits a good ability in zero-shot retrieval scenarios.