 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePower to the Points: Validating Data Memberships in Clusterings
Paper and Code
May 21, 2013
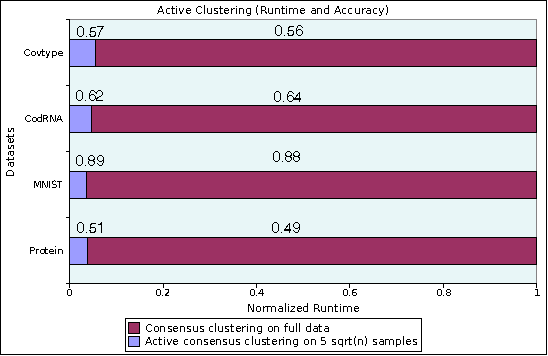
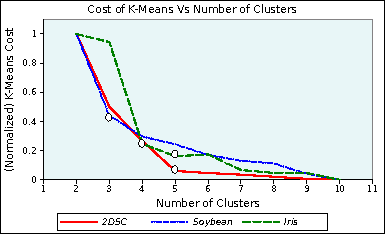
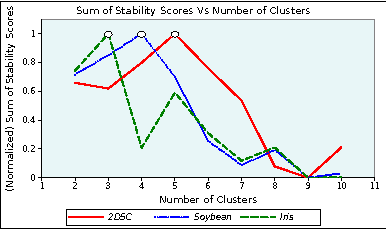
A clustering is an implicit assignment of labels of points, based on proximity to other points. It is these labels that are then used for downstream analysis (either focusing on individual clusters, or identifying representatives of clusters and so on). Thus, in order to trust a clustering as a first step in exploratory data analysis, we must trust the labels assigned to individual data. Without supervision, how can we validate this assignment? In this paper, we present a method to attach affinity scores to the implicit labels of individual points in a clustering. The affinity scores capture the confidence level of the cluster that claims to "own" the point. This method is very general: it can be used with clusterings derived from Euclidean data, kernelized data, or even data derived from information spaces. It smoothly incorporates importance functions on clusters, allowing us to eight different clusters differently. It is also efficient: assigning an affinity score to a point depends only polynomially on the number of clusters and is independent of the number of points in the data. The dimensionality of the underlying space only appears in preprocessing. We demonstrate the value of our approach with an experimental study that illustrates the use of these scores in different data analysis tasks, as well as the efficiency and flexibility of the method. We also demonstrate useful visualizations of these scores; these might prove useful within an interactive analytics framework.