 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoverty Mapping Using Convolutional Neural Networks Trained on High and Medium Resolution Satellite Images, With an Application in Mexico
Paper and Code
Nov 16, 2017
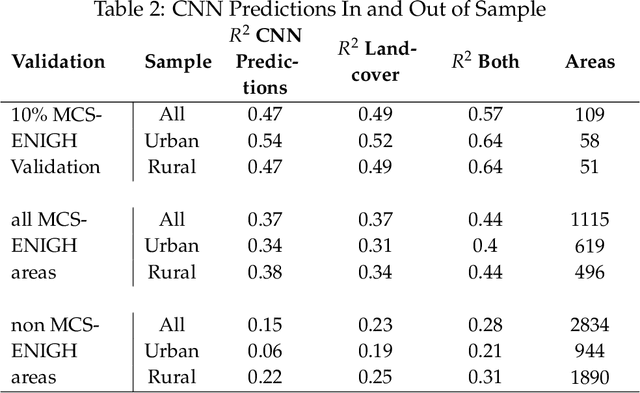
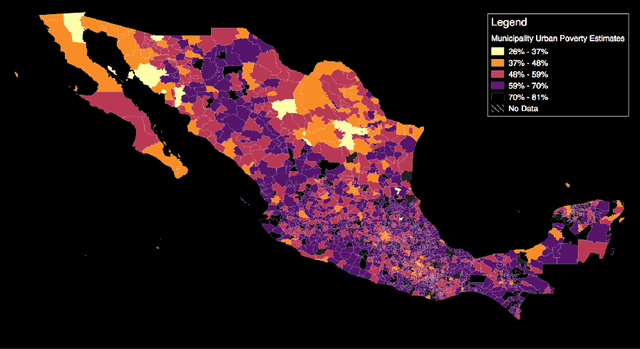
Mapping the spatial distribution of poverty in developing countries remains an important and costly challenge. These "poverty maps" are key inputs for poverty targeting, public goods provision, political accountability, and impact evaluation, that are all the more important given the geographic dispersion of the remaining bottom billion severely poor individuals. In this paper we train Convolutional Neural Networks (CNNs) to estimate poverty directly from high and medium resolution satellite images. We use both Planet and Digital Globe imagery with spatial resolutions of 3-5 sq. m. and 50 sq. cm. respectively, covering all 2 million sq. km. of Mexico. Benchmark poverty estimates come from the 2014 MCS-ENIGH combined with the 2015 Intercensus and are used to estimate poverty rates for 2,456 Mexican municipalities. CNNs are trained using the 896 municipalities in the 2014 MCS-ENIGH. We experiment with several architectures (GoogleNet, VGG) and use GoogleNet as a final architecture where weights are fine-tuned from ImageNet. We find that 1) the best models, which incorporate satellite-estimated land use as a predictor, explain approximately 57% of the variation in poverty in a validation sample of 10 percent of MCS-ENIGH municipalities; 2) Across all MCS-ENIGH municipalities explanatory power reduces to 44% in a CNN prediction and landcover model; 3) Predicted poverty from the CNN predictions alone explains 47% of the variation in poverty in the validation sample, and 37% over all MCS-ENIGH municipalities; 4) In urban areas we see slight improvements from using Digital Globe versus Planet imagery, which explain 61% and 54% of poverty variation respectively. We conclude that CNNs can be trained end-to-end on satellite imagery to estimate poverty, although there is much work to be done to understand how the training process influences out of sample validation.