 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePost-mortem on a deep learning contest: a Simpson's paradox and the complementary roles of scale metrics versus shape metrics
Paper and Code
Jun 01, 2021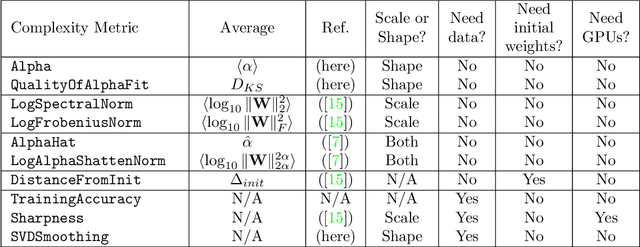

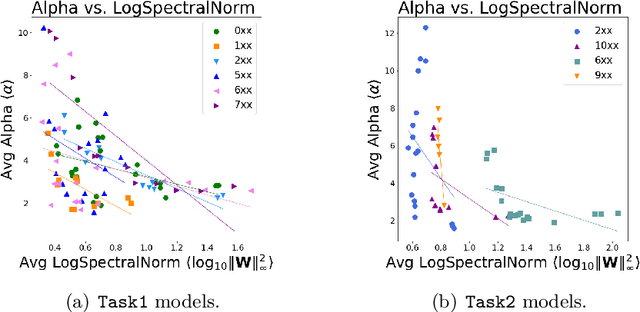
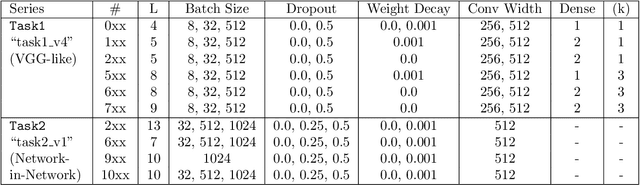
To understand better the causes of good generalization performance in state-of-the-art neural network (NN) models, we analyze of a corpus of models that was made publicly-available for a contest to predict the generalization accuracy of NNs. These models include a wide range of qualities and were trained with a range of architectures and regularization hyperparameters. We identify what amounts to a Simpson's paradox: where "scale" metrics (from traditional statistical learning theory) perform well overall but perform poorly on subpartitions of the data of a given depth, when regularization hyperparameters are varied; and where "shape" metrics (from Heavy-Tailed Self Regularization theory) perform well on subpartitions of the data, when hyperparameters are varied for models of a given depth, but perform poorly overall when models with varying depths are aggregated. Our results highlight the subtly of comparing models when both architectures and hyperparameters are varied, as well as the complementary role of implicit scale versus implicit shape parameters in understanding NN model quality. Our results also suggest caution when one tries to extract causal insight with a single metric applied to aggregate data, and they highlight the need to go beyond one-size-fits-all metrics based on upper bounds from generalization theory to describe the performance of state-of-the-art NN models. Based on these findings, we present two novel shape metrics, one data-independent, and the other data-dependent, which can predict trends in the test accuracy of a series of NNs, of a fixed architecture/depth, when varying solver hyperparameters.