 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePositive-Negative Momentum: Manipulating Stochastic Gradient Noise to Improve Generalization
Paper and Code


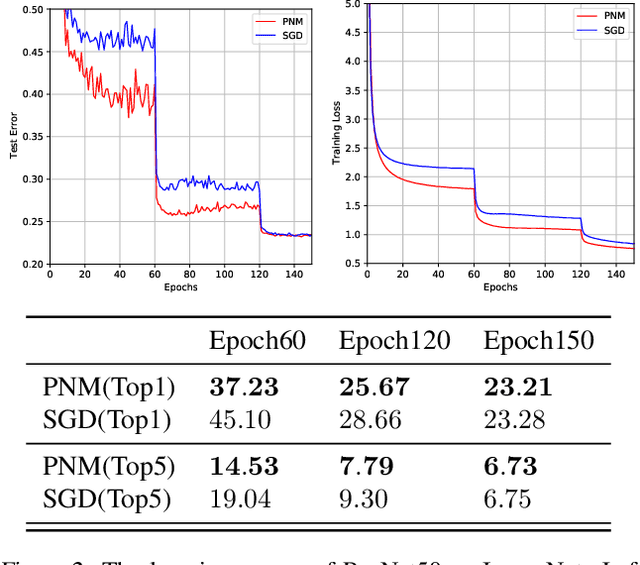

It is well-known that stochastic gradient noise (SGN) acts as implicit regularization for deep learning and is essentially important for both optimization and generalization of deep networks. Some works attempted to artificially simulate SGN by injecting random noise to improve deep learning. However, it turned out that the injected simple random noise cannot work as well as SGN, which is anisotropic and parameter-dependent. For simulating SGN at low computational costs and without changing the learning rate or batch size, we propose the Positive-Negative Momentum (PNM) approach that is a powerful alternative to conventional Momentum in classic optimizers. The introduced PNM method maintains two approximate independent momentum terms. Then, we can control the magnitude of SGN explicitly by adjusting the momentum difference. We theoretically prove the convergence guarantee and the generalization advantage of PNM over Stochastic Gradient Descent (SGD). By incorporating PNM into the two conventional optimizers, SGD with Momentum and Adam, our extensive experiments empirically verified the significant advantage of the PNM-based variants over the corresponding conventional Momentum-based optimizers. Code: \url{https://github.com/zeke-xie/Positive-Negative-Momentum}.