 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoseContrast: Class-Agnostic Object Viewpoint Estimation in the Wild with Pose-Aware Contrastive Learning
Paper and Code

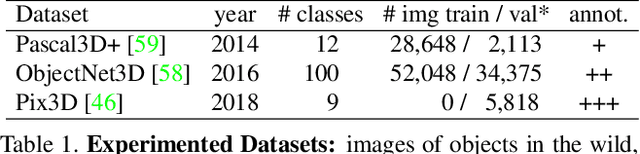
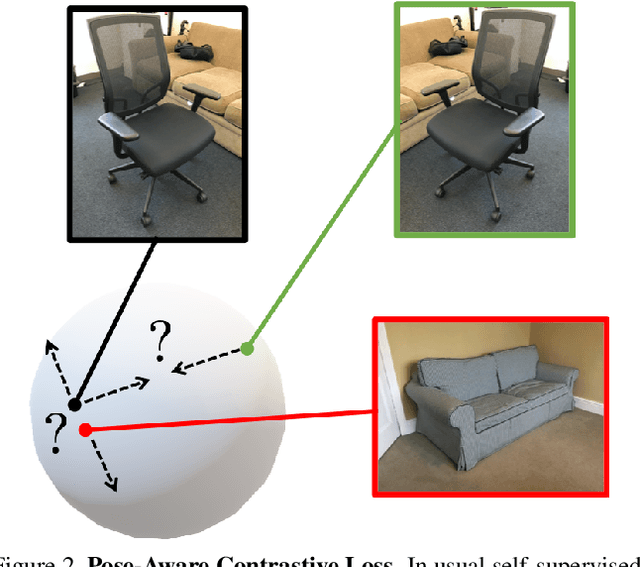
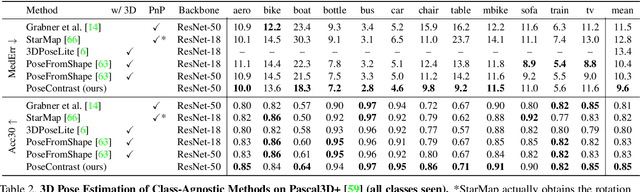
Motivated by the need of estimating the pose (viewpoint) of arbitrary objects in the wild, which is only covered by scarce and small datasets, we consider the challenging problem of class-agnostic 3D object pose estimation, with no 3D shape knowledge. The idea is to leverage features learned on seen classes to estimate the pose for classes that are unseen, yet that share similar geometries and canonical frames with seen classes. For this, we train a direct pose estimator in a class-agnostic way by sharing weights across all object classes, and we introduce a contrastive learning method that has three main ingredients: (i) the use of pre-trained, self-supervised, contrast-based features; (ii) pose-aware data augmentations; (iii) a pose-aware contrastive loss. We experimented on Pascal3D+ and ObjectNet3D, as well as Pix3D in a cross-dataset fashion, with both seen and unseen classes. We report state-of-the-art results, including against methods that use additional shape information, and also when we use detected bounding boxes.