Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolitical claim identification and categorization in a multilingual setting: First experiments
Paper and Code
Oct 13, 2023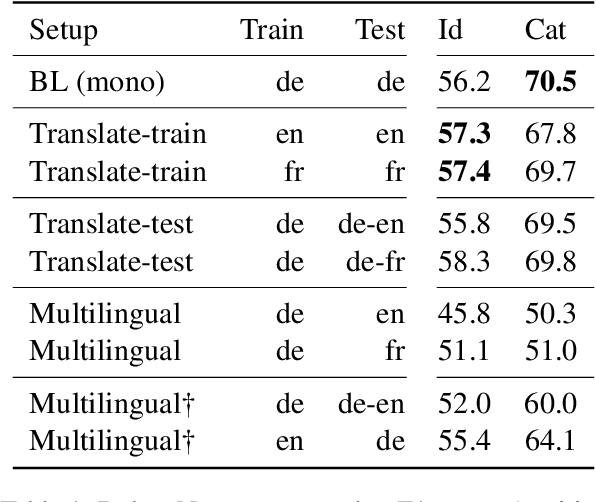



The identification and classification of political claims is an important step in the analysis of political newspaper reports; however, resources for this task are few and far between. This paper explores different strategies for the cross-lingual projection of political claims analysis. We conduct experiments on a German dataset, DebateNet2.0, covering the policy debate sparked by the 2015 refugee crisis. Our evaluation involves two tasks (claim identification and categorization), three languages (German, English, and French) and two methods (machine translation -- the best method in our experiments -- and multilingual embeddings).
* Presented at KONVENS 2023, Ingolstadt, Germany
View paper on