 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy Trees for Prediction: Interpretable and Adaptive Model Selection for Machine Learning
Paper and Code
May 30, 2024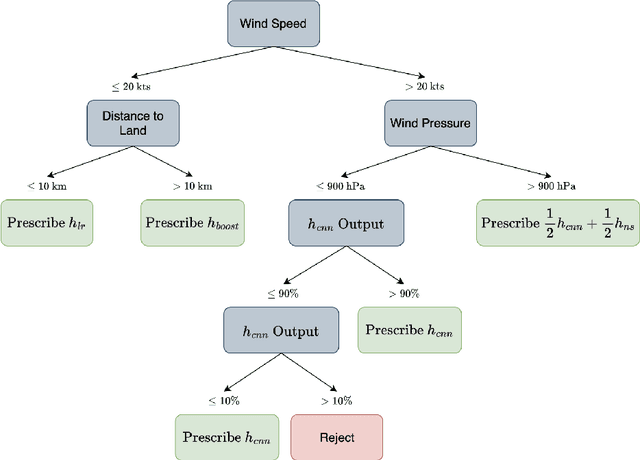

As a multitude of capable machine learning (ML) models become widely available in forms such as open-source software and public APIs, central questions remain regarding their use in real-world applications, especially in high-stakes decision-making. Is there always one best model that should be used? When are the models likely to be error-prone? Should a black-box or interpretable model be used? In this work, we develop a prescriptive methodology to address these key questions, introducing a tree-based approach, Optimal Predictive-Policy Trees (OP2T), that yields interpretable policies for adaptively selecting a predictive model or ensemble, along with a parameterized option to reject making a prediction. We base our methods on learning globally optimized prescriptive trees. Our approach enables interpretable and adaptive model selection and rejection while only assuming access to model outputs. By learning policies over different feature spaces, including the model outputs, our approach works with both structured and unstructured datasets. We evaluate our approach on real-world datasets, including regression and classification tasks with both structured and unstructured data. We demonstrate that our approach provides both strong performance against baseline methods while yielding insights that help answer critical questions about which models to use, and when.