 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy-Aware Model Learning for Policy Gradient Methods
Paper and Code
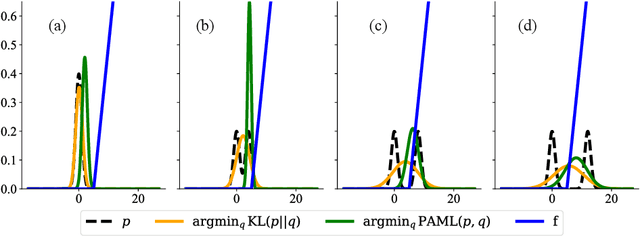


This paper considers the problem of learning a model in model-based reinforcement learning (MBRL). We examine how the planning module of an MBRL algorithm uses the model, and propose that the model learning module should incorporate the way the planner is going to use the model. This is in contrast to conventional model learning approaches, such as those based on maximum likelihood estimate, that learn a predictive model of the environment without explicitly considering the interaction of the model and the planner. We focus on policy gradient type of planning algorithms and derive new loss functions for model learning that incorporate how the planner uses the model. We call this approach Policy-Aware Model Learning (PAML). We theoretically analyze a generic model-based policy gradient algorithm and provide a convergence guarantee for the optimized policy. We also empirically evaluate PAML on some benchmark problems, showing promising results.