 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlausible May Not Be Faithful: Probing Object Hallucination in Vision-Language Pre-training
Paper and Code
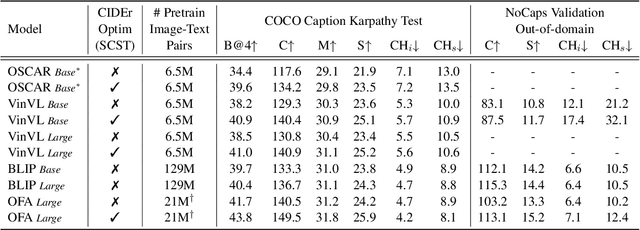


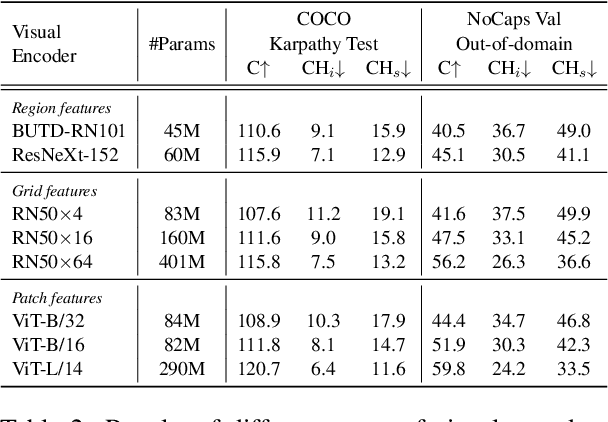
Large-scale vision-language pre-trained (VLP) models are prone to hallucinate non-existent visual objects when generating text based on visual information. In this paper, we exhaustively probe the object hallucination problem from three aspects. First, we examine various state-of-the-art VLP models, showing that models achieving better scores on standard metrics(e.g., BLEU-4, CIDEr) could hallucinate objects more frequently. Second, we investigate how different types of visual features in VLP influence hallucination, including region-based, grid-based, and patch-based. Surprisingly, we find that patch-based features perform the best and smaller patch resolution yields a non-trivial reduction in object hallucination. Third, we decouple various VLP objectives and demonstrate their effectiveness in alleviating object hallucination. Based on that, we propose a new pre-training loss, object masked language modeling, to further reduce object hallucination. We evaluate models on both COCO (in-domain) and NoCaps (out-of-domain) datasets with our improved CHAIR metric. Furthermore, we investigate the effects of various text decoding strategies and image augmentation methods on object hallucination.