 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePipAttack: Poisoning Federated Recommender Systems forManipulating Item Promotion
Paper and Code
Oct 21, 2021
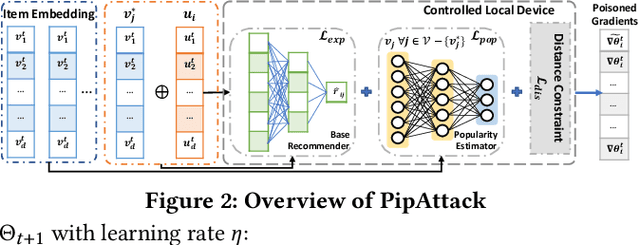
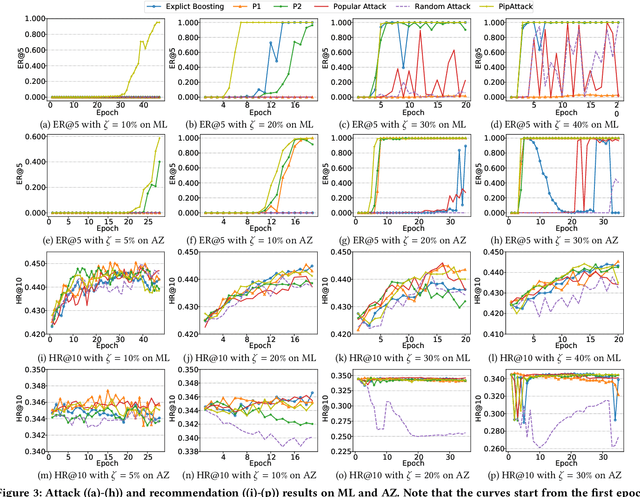

Due to the growing privacy concerns, decentralization emerges rapidly in personalized services, especially recommendation. Also, recent studies have shown that centralized models are vulnerable to poisoning attacks, compromising their integrity. In the context of recommender systems, a typical goal of such poisoning attacks is to promote the adversary's target items by interfering with the training dataset and/or process. Hence, a common practice is to subsume recommender systems under the decentralized federated learning paradigm, which enables all user devices to collaboratively learn a global recommender while retaining all the sensitive data locally. Without exposing the full knowledge of the recommender and entire dataset to end-users, such federated recommendation is widely regarded `safe' towards poisoning attacks. In this paper, we present a systematic approach to backdooring federated recommender systems for targeted item promotion. The core tactic is to take advantage of the inherent popularity bias that commonly exists in data-driven recommenders. As popular items are more likely to appear in the recommendation list, our innovatively designed attack model enables the target item to have the characteristics of popular items in the embedding space. Then, by uploading carefully crafted gradients via a small number of malicious users during the model update, we can effectively increase the exposure rate of a target (unpopular) item in the resulted federated recommender. Evaluations on two real-world datasets show that 1) our attack model significantly boosts the exposure rate of the target item in a stealthy way, without harming the accuracy of the poisoned recommender; and 2) existing defenses are not effective enough, highlighting the need for new defenses against our local model poisoning attacks to federated recommender systems.