 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePillarNet: Real-Time and High-Performance Pillar-based 3D Object Detection
Paper and Code

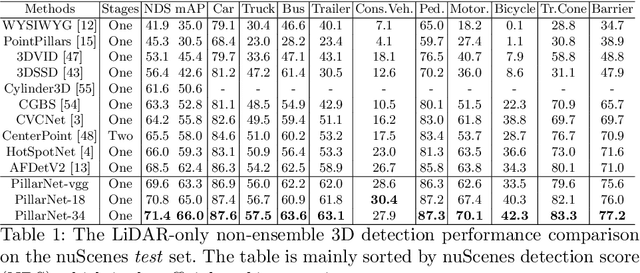
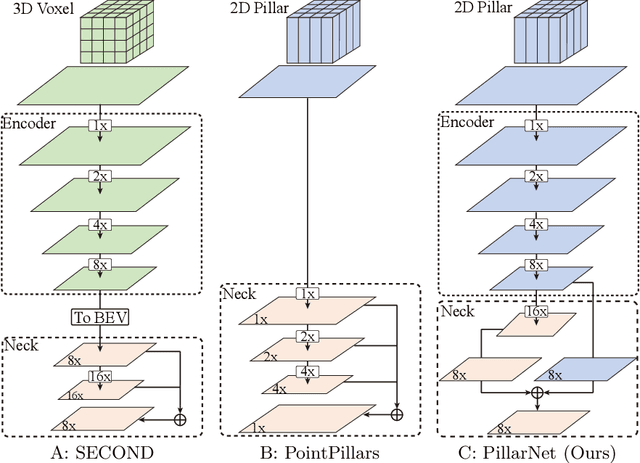

Real-time and high-performance 3D object detection is of critical importance for autonomous driving. Recent top-performing 3D object detectors mainly rely on point-based or 3D voxel-based convolutions, which are both computationally inefficient for onboard deployment. While recent researches focus on point-based or 3D voxel-based convolutions for higher performance, these methods fail to meet latency and power efficiency requirements especially for deployment on embedded devices. In contrast, pillar-based methods use merely 2D convolutions, which consume less computation resources, but they lag far behind their voxel-based counterparts in detection accuracy. However, the superiority of such 3D voxel-based methods over pillar-based methods is still broadly attributed to the effectiveness of 3D convolution neural network (CNN). In this paper, by examining the primary performance gap between pillar- and voxel-based detectors, we develop a real-time and high-performance pillar-based detector, dubbed PillarNet. The proposed PillarNet consists of a powerful encoder network for effective pillar feature learning, a neck network for spatial-semantic feature fusion and the commonly used detect head. Using only 2D convolutions, PillarNet is flexible to an optional pillar size and compatible with classical 2D CNN backbones, such as VGGNet and ResNet. Additionally, PillarNet benefits from our designed orientation-decoupled IoU regression loss along with the IoU-aware prediction branch. Extensive experimental results on large-scale nuScenes Dataset and Waymo Open Dataset demonstrate that the proposed PillarNet performs well over the state-of-the-art 3D detectors in terms of effectiveness and efficiency. Code will be made publicly available.