 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePiggyback: Adapting a Single Network to Multiple Tasks by Learning to Mask Weights
Paper and Code
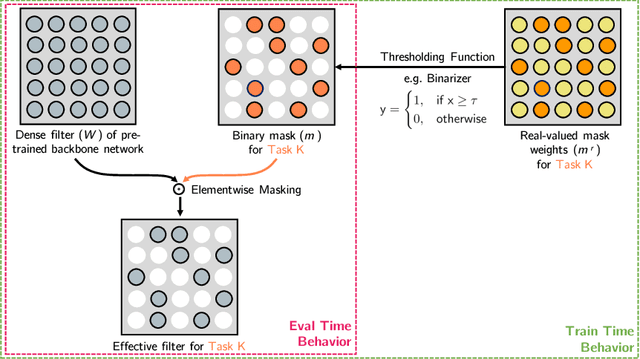

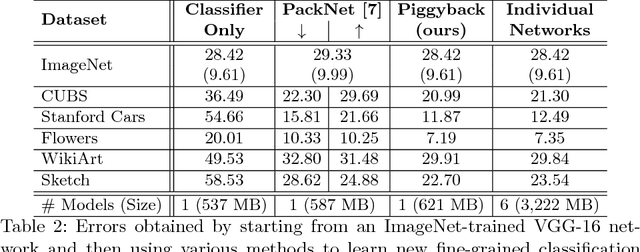
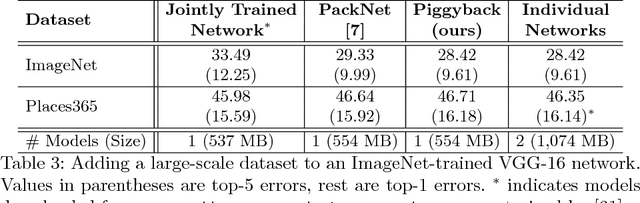
This work presents a method for adapting a single, fixed deep neural network to multiple tasks without affecting performance on already learned tasks. By building upon ideas from network quantization and pruning, we learn binary masks that piggyback on an existing network, or are applied to unmodified weights of that network to provide good performance on a new task. These masks are learned in an end-to-end differentiable fashion, and incur a low overhead of 1 bit per network parameter, per task. Even though the underlying network is fixed, the ability to mask individual weights allows for the learning of a large number of filters. We show performance comparable to dedicated fine-tuned networks for a variety of classification tasks, including those with large domain shifts from the initial task (ImageNet), and a variety of network architectures. Unlike prior work, we do not suffer from catastrophic forgetting or competition between tasks, and our performance is agnostic to task ordering. Code available at https://github.com/arunmallya/piggyback.