 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePiecewise convexity of artificial neural networks
Paper and Code
Dec 28, 2016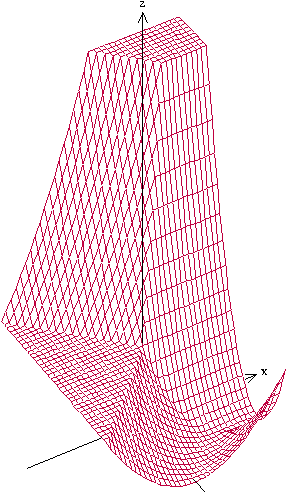
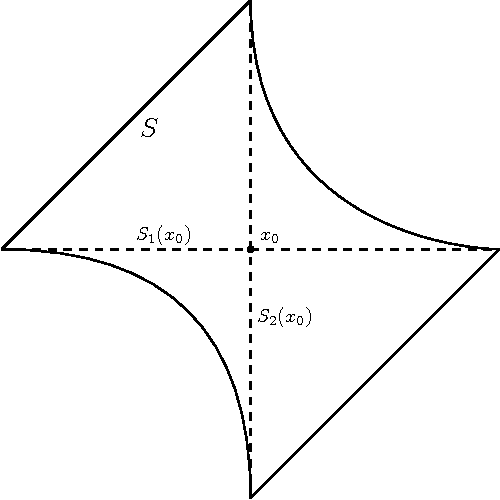
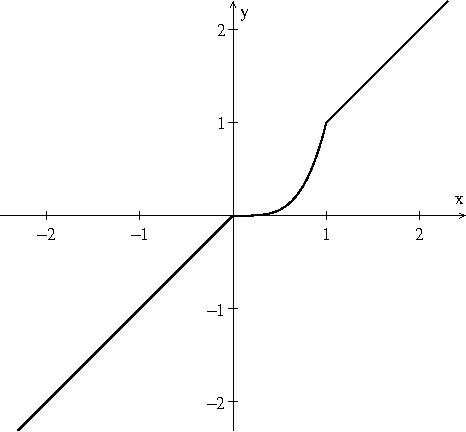
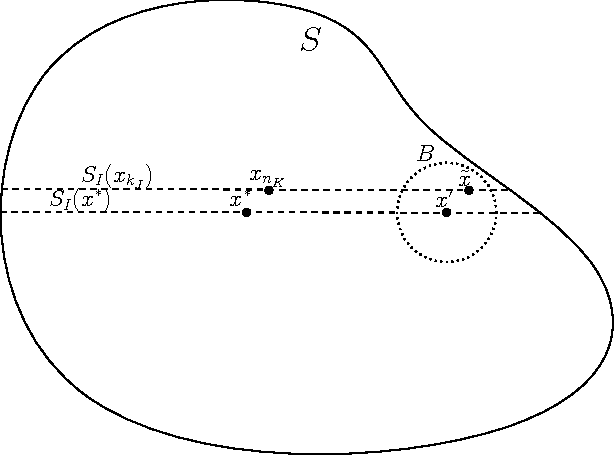
Although artificial neural networks have shown great promise in applications including computer vision and speech recognition, there remains considerable practical and theoretical difficulty in optimizing their parameters. The seemingly unreasonable success of gradient descent methods in minimizing these non-convex functions remains poorly understood. In this work we offer some theoretical guarantees for networks with piecewise affine activation functions, which have in recent years become the norm. We prove three main results. Firstly, that the network is piecewise convex as a function of the input data. Secondly, that the network, considered as a function of the parameters in a single layer, all others held constant, is again piecewise convex. Finally, that the network as a function of all its parameters is piecewise multi-convex, a generalization of biconvexity. From here we characterize the local minima and stationary points of the training objective, showing that they minimize certain subsets of the parameter space. We then analyze the performance of two optimization algorithms on multi-convex problems: gradient descent, and a method which repeatedly solves a number of convex sub-problems. We prove necessary convergence conditions for the first algorithm and both necessary and sufficient conditions for the second, after introducing regularization to the objective. Finally, we remark on the remaining difficulty of the global optimization problem. Under the squared error objective, we show that by varying the training data, a single rectifier neuron admits local minima arbitrarily far apart, both in objective value and parameter space.