 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePiecewise Approximations of Black Box Models for Model Interpretation
Paper and Code
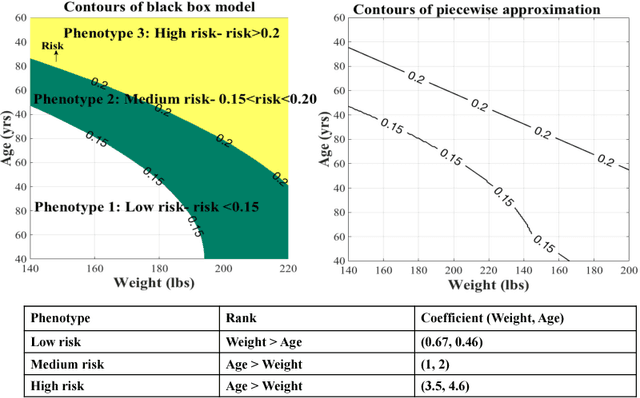

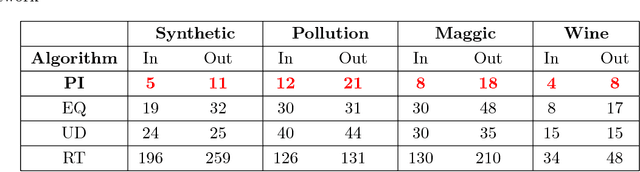
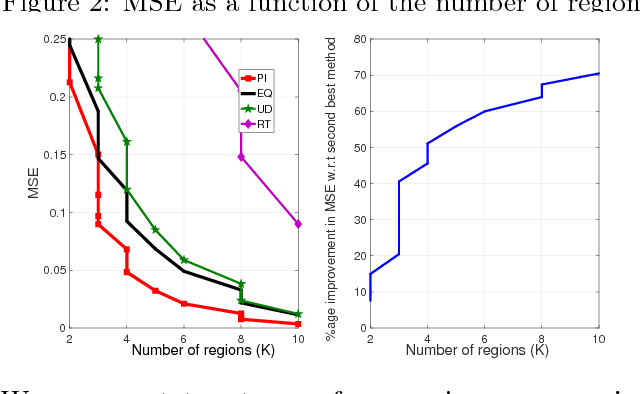
Machine Learning models have proved extremely successful for a wide variety of supervised learning problems, but the predictions of many of these models are difficult to interpret. A recent literature interprets the predictions of more general "black-box" machine learning models by approximating these models in terms of simpler models such as piecewise linear or piecewise constant models. Existing literature constructs these approximations in an ad-hoc manner. We provide a tractable dynamic programming algorithm that partitions the feature space into clusters in a principled way and then uses this partition to provide both piecewise constant and piecewise linear interpretations of an arbitrary "black-box" model. When loss is measured in terms of mean squared error, our approximation is optimal (under certain conditions); for more general loss functions, our interpretation is probably approximately optimal (in the sense of PAC learning). Experiments with real and synthetic data show that it continues to provide significant improvements (in terms of mean squared error) over competing approaches.