 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-informed deep learning and compressive collocation for high-dimensional diffusion-reaction equations: practical existence theory and numerics
Paper and Code
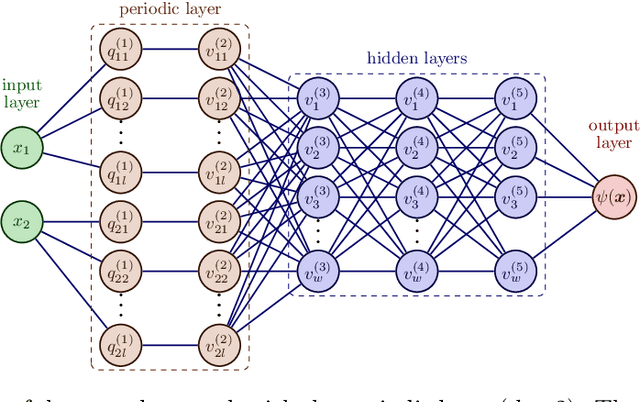
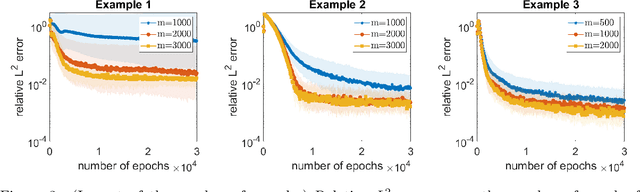
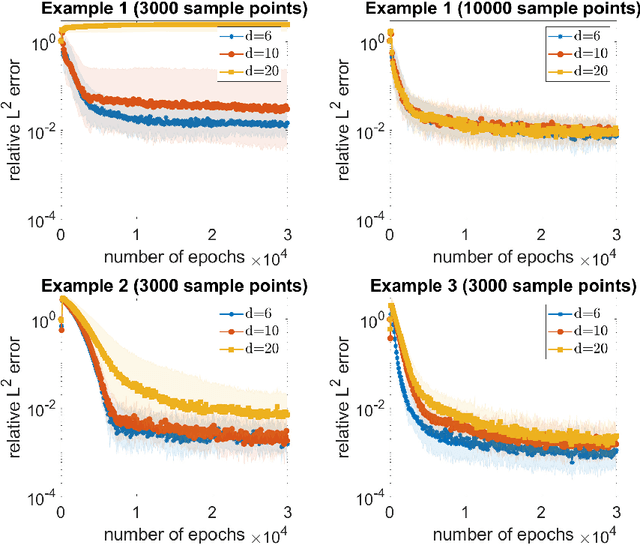
On the forefront of scientific computing, Deep Learning (DL), i.e., machine learning with Deep Neural Networks (DNNs), has emerged a powerful new tool for solving Partial Differential Equations (PDEs). It has been observed that DNNs are particularly well suited to weakening the effect of the curse of dimensionality, a term coined by Richard E. Bellman in the late `50s to describe challenges such as the exponential dependence of the sample complexity, i.e., the number of samples required to solve an approximation problem, on the dimension of the ambient space. However, although DNNs have been used to solve PDEs since the `90s, the literature underpinning their mathematical efficiency in terms of numerical analysis (i.e., stability, accuracy, and sample complexity), is only recently beginning to emerge. In this paper, we leverage recent advancements in function approximation using sparsity-based techniques and random sampling to develop and analyze an efficient high-dimensional PDE solver based on DL. We show, both theoretically and numerically, that it can compete with a novel stable and accurate compressive spectral collocation method. In particular, we demonstrate a new practical existence theorem, which establishes the existence of a class of trainable DNNs with suitable bounds on the network architecture and a sufficient condition on the sample complexity, with logarithmic or, at worst, linear scaling in dimension, such that the resulting networks stably and accurately approximate a diffusion-reaction PDE with high probability.