 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhylogeny-Inspired Adaptation of Multilingual Models to New Languages
Paper and Code
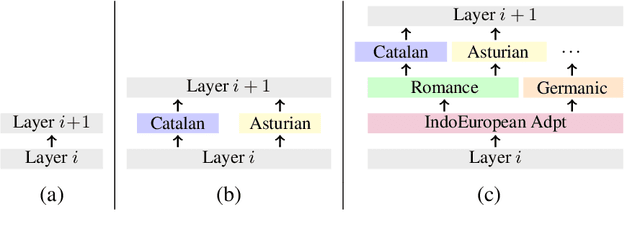
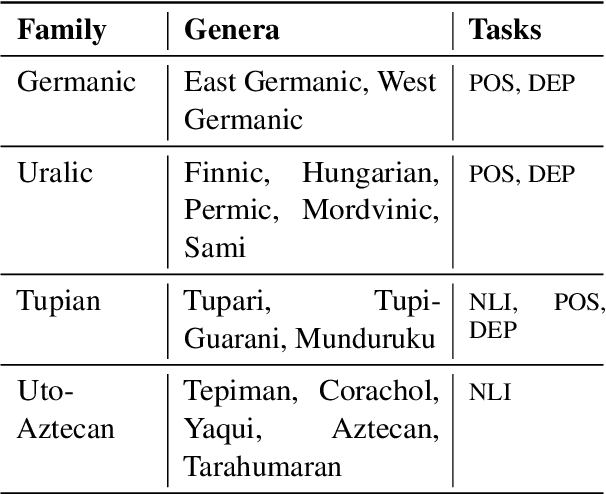
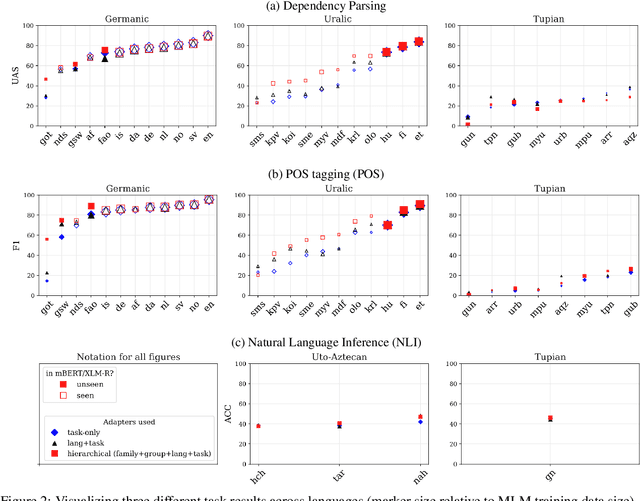

Large pretrained multilingual models, trained on dozens of languages, have delivered promising results due to cross-lingual learning capabilities on variety of language tasks. Further adapting these models to specific languages, especially ones unseen during pre-training, is an important goal towards expanding the coverage of language technologies. In this study, we show how we can use language phylogenetic information to improve cross-lingual transfer leveraging closely related languages in a structured, linguistically-informed manner. We perform adapter-based training on languages from diverse language families (Germanic, Uralic, Tupian, Uto-Aztecan) and evaluate on both syntactic and semantic tasks, obtaining more than 20% relative performance improvements over strong commonly used baselines, especially on languages unseen during pre-training.