 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePHEONA: An Evaluation Framework for Large Language Model-based Approaches to Computational Phenotyping
Paper and Code
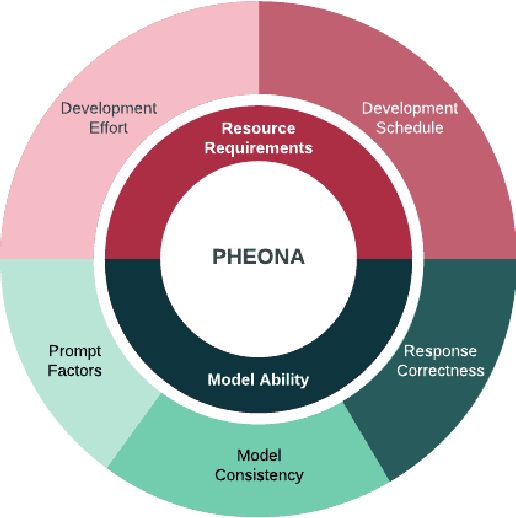
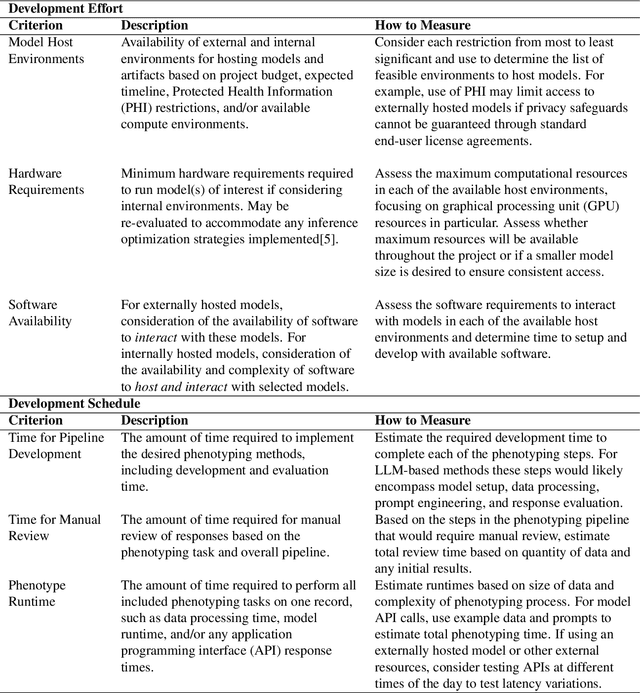
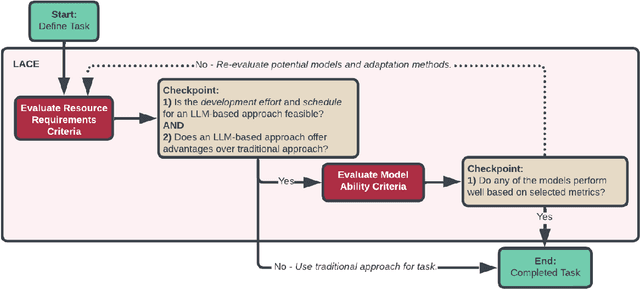
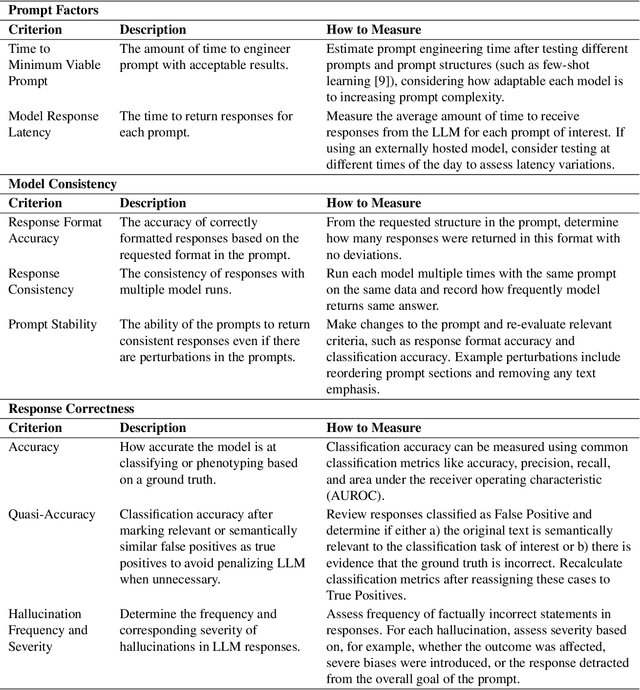
Computational phenotyping is essential for biomedical research but often requires significant time and resources, especially since traditional methods typically involve extensive manual data review. While machine learning and natural language processing advancements have helped, further improvements are needed. Few studies have explored using Large Language Models (LLMs) for these tasks despite known advantages of LLMs for text-based tasks. To facilitate further research in this area, we developed an evaluation framework, Evaluation of PHEnotyping for Observational Health Data (PHEONA), that outlines context-specific considerations. We applied and demonstrated PHEONA on concept classification, a specific task within a broader phenotyping process for Acute Respiratory Failure (ARF) respiratory support therapies. From the sample concepts tested, we achieved high classification accuracy, suggesting the potential for LLM-based methods to improve computational phenotyping processes.