 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhases of learning dynamics in artificial neural networks: with or without mislabeled data
Paper and Code
Jan 16, 2021
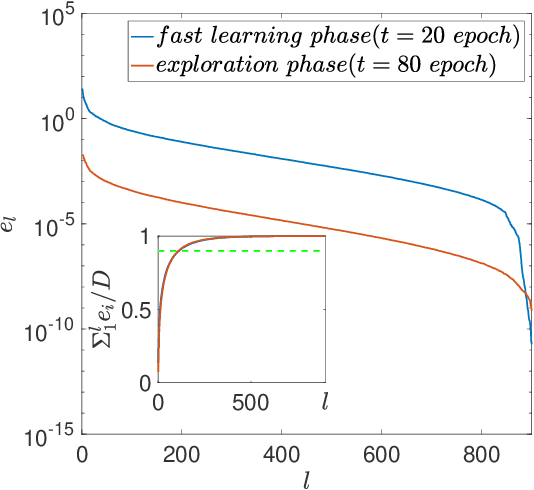

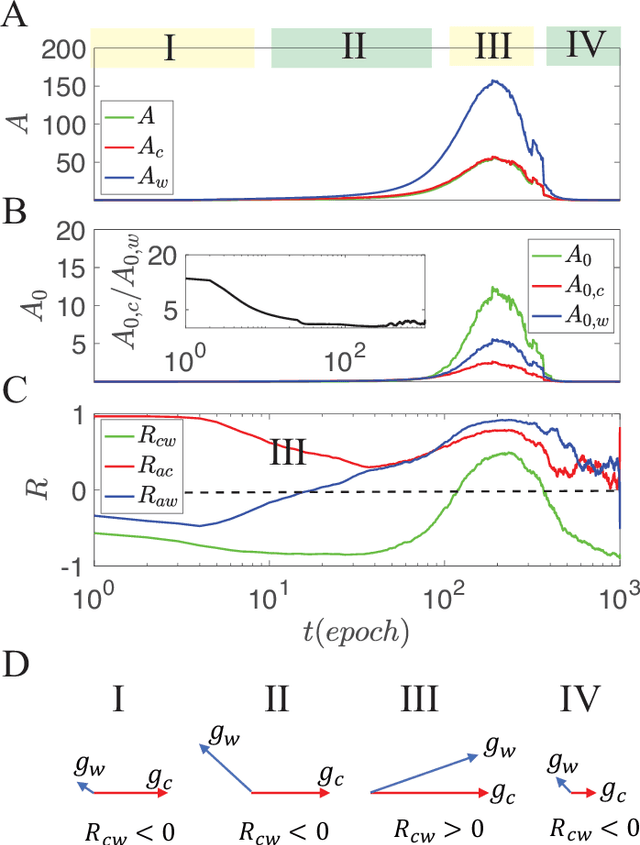
Despite tremendous success of deep neural network in machine learning, the underlying reason for its superior learning capability remains unclear. Here, we present a framework based on statistical physics to study dynamics of stochastic gradient descent (SGD) that drives learning in neural networks. By using the minibatch gradient ensemble, we construct order parameters to characterize dynamics of weight updates in SGD. Without mislabeled data, we find that the SGD learning dynamics transitions from a fast learning phase to a slow exploration phase, which is associated with large changes in order parameters that characterize the alignment of SGD gradients and their mean amplitude. In the case with randomly mislabeled samples, SGD learning dynamics falls into four distinct phases. The system first finds solutions for the correctly labeled samples in phase I, it then wanders around these solutions in phase II until it finds a direction to learn the mislabeled samples during phase III, after which it finds solutions that satisfy all training samples during phase IV. Correspondingly, the test error decreases during phase I and remains low during phase II; however, it increases during phase III and reaches a high plateau during phase IV. The transitions between different phases can be understood by changes of order parameters that characterize the alignment of mean gradients for the correctly and incorrectly labeled samples and their (relative) strength during learning. We find that individual sample losses for the two datasets are most separated during phase II, which leads to a cleaning process to eliminate mislabeled samples for improving generalization.