 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalized Decentralized Federated Learning with Knowledge Distillation
Paper and Code
Feb 23, 2023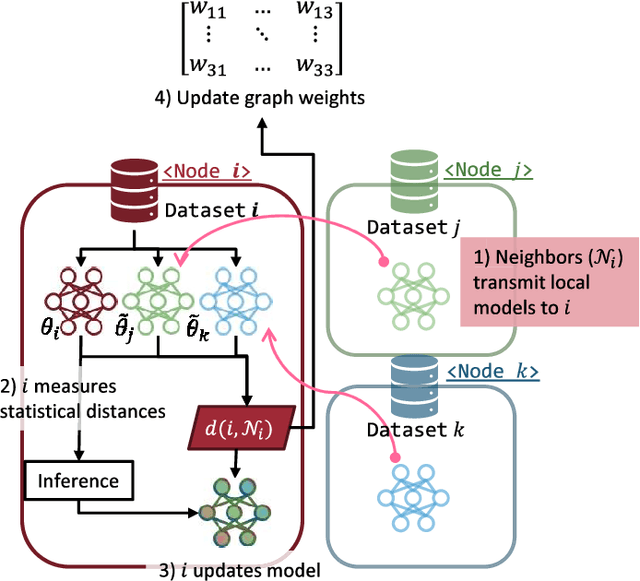
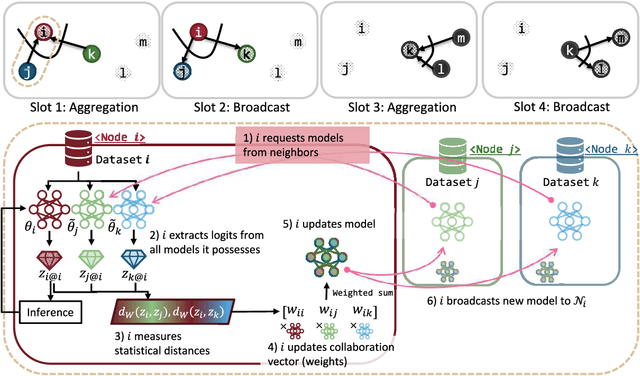
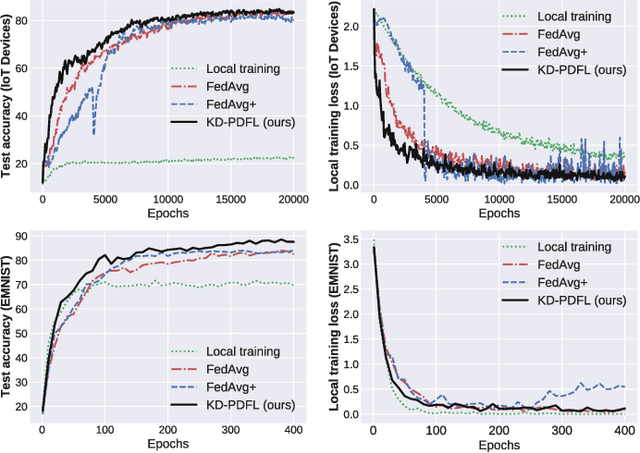

Personalization in federated learning (FL) functions as a coordinator for clients with high variance in data or behavior. Ensuring the convergence of these clients' models relies on how closely users collaborate with those with similar patterns or preferences. However, it is generally challenging to quantify similarity under limited knowledge about other users' models given to users in a decentralized network. To cope with this issue, we propose a personalized and fully decentralized FL algorithm, leveraging knowledge distillation techniques to empower each device so as to discern statistical distances between local models. Each client device can enhance its performance without sharing local data by estimating the similarity between two intermediate outputs from feeding local samples as in knowledge distillation. Our empirical studies demonstrate that the proposed algorithm improves the test accuracy of clients in fewer iterations under highly non-independent and identically distributed (non-i.i.d.) data distributions and is beneficial to agents with small datasets, even without the need for a central server.